

I. 서 론
수동 소나는 수중 및 수상 표적이 방사하는 소음을 획득하여 표적을 탐지하는 시스템으로, 표적을 탐지하기 위해 선배열, 원통형 배열 등의 센서 배열을 통해 음향 신호를 수신하고 획득된 신호에 빔형성 및 광대역/협대역 탐지 등의 신호처리를 수행한다. 협대역 신호를 탐지하기 위한 대표적인 신호처리 방법으로는 LOw Frequency Analysis Recording(LOFAR) 또는 Demodulation of Envelop Modulation On Noise(DEMON) 등이 있으며, 해당 그램의 토널 성분을 확인하는 방식으로 표적을 탐지 및 식별한다. LOFAR는 표적이 방사하는 소음의 협대역 토널 성분을 확인하는 방법으로 빔데이터를 주파수 파워 스펙트럼으로 변환하고 적분 및 규준화 등의 처리를 통해 생성된다. LOFAR는 전시 방법에 따라 프레임 별 빔/주파수 화면인 FRequency-AZimuth(FRAZ)나 빔 별 시간/주파수 화면인 Frequency Time Records(FTR) 등의 형태로 전시된다. LOFAR는 매 프레임마다 생성되는 빔/주파수빈에 대한 파워 스펙트럼을 의미하며, FRAZ와 FTR은 파워 스펙트럼 값을 주파수, 빔, 시간에 대해 재배열하여 전시하는 방식을 나타낸다. DEMON은 표적의 프로펠러 회전과 공동 현상에 의해 발생하는 소음의 토널 성분을 확인하는 방법으로 빔 데이터에 대한 포락선을 검출하고 이를 다시 주파수 스펙트럼으로 변환한다. LOFAR와 마찬가지로 DEMON 생성 시에도 적분 및 규준화 등의 후처리를 적용하며, 빔/주파수빈에 대한 파워 스펙트럼의 구조를 갖는다.
최근에는 수동소나의 탐지 성능을 높이기 위해 빔개수와 주파수 해상도를 높이는 경우가 증가하고 있다. LOFAR와 DEMON과 같은 협대역 탐지 기법은 매 프레임 별로 빔/주파수 빈의 파워 스펙트럼을 생성하기 때문에 빔과 주파수 빈 개수를 늘리면, 스펙트럼의 데이터 량도 증가하게 된다. 예를 들어 빔 개수가 100개이고 1 Hz 해상도로 100 Hz ~ 200 Hz의 저주파 대역에 대한 LOFAR를 생성한다고 할 때, 프레임 별 파워는 100 × 100개가 된다. 여기서 해상도를 0.5 Hz로 빔 개수를 200개로 높인다고 하면, 파워 스펙트럼 데이터는 200 × 200으로 네 배가 증가하게 된다. 이처럼 LOFAR와 DEMON에 대한 데이터량은 지속적으로 증가하는 추세이나, 이를 저장 및 전송하기 위한 대비는 미비한 실정이다. 고용량의 LOFAR와 DEMON 그램을 저장 및 전송하기 위해서는 저장 용량 및 전송 대역폭 확보가 필요하며, 그램에 대한 압축 기법이 선행적으로 적용되어야 한다. 하지만 LOFAR와 DEMON 그램에 특화된 압축 기법 연구는 전무하며 Zip 등의 일반적인 데이터 압축 기법을 적용하는 것만 가능한 상황이다.
본 논문에서는 LOFAR와 DEMON 그램에 특화된 압축 기법을 제안한다. LOFAR/DEMON 그램은 프레임단위로 생성되며 방위-주파수의 2차원 데이터 구조를 갖는다. 이러한 구조는 일반적인 동영상과 유사하나, 비디오 압축 코덱을 LOFAR/DEMON 그램 압축에 직접적으로 적용하기는 어렵다. 우선 압축하려고 하는 LOFAR/DEMON 그램 데이터는 Byte 크기의 데이터가 아니다. 영상은 기본적으로 픽셀의 화소가 0 ~ 255크기의 Byte로 한정되어 있으며 그에 대한 분석 등을 과정을 통해 최적화된 압축 결과를 도출한다. 반면, LOFAR/DEMON 그램은 float/double 형태의 데이터로 일반적인 영상과 차이가 있다. 또한, LOFAR/DEMON 그램은 프래임에서 가로/세로에 대한 차원 정보가 다르다. 영상은 가로, 세로에 대한 특성이 다르지 않기 때문에 정사각형 또는 직사각형 블록 크기로 분할하여 압축을 수행한다. 반면 LOFAR/DEMON 그램은 영상처럼 단순한 2차원 공간이 아니라 빔, 주파수로 두 차원간의 특성이 같지 않다. 마지막으로 LOFAR/DEMON 그램은 0에 해당하는 값들이 산발적으로 나타나는 특성을 보인다. 이는 노이즈 특성에 해당되는데 보통 가우시안 노이즈는 평균이 0이기 때문에 0에 가까운 값이 많이 나타난다. 하지만 비디오와 같이 특정 영역이 전부 유사한 값을 갖는 형태가 아니라 산발적으로 0의 값이 나오는 패턴이기 때문에 비디오 코덱에서의 블록 단위의 예측을 직접적으로 적용하기 어렵다. 이러한 이유로 비디오 압축 코덱을 바로 적용하여 LOFAR /DEMON 그램 데이터를 압축하기에는 제안 사항이 많다. 제안하는 기법의 부호기는 널리 알려진 비디오 압축 코덱의 기본 개념을 LOFAR/DEMON 그램 데이터 특성에 맞게 변환 및 확장한 코덱으로 프레임 별 파워 스펙트럼에 대해 전처리, 예측, 보상, 엔트로피 부호화 등의 과정 등을 수행하여 파워 스펙트럼을 비트 스트림으로 변환한다.
본 논문의 구성은 다음과 같다. II장에서는 제안하는 압축 기법의 개요에 대해 설명한다. III장에서는 부호기/복호기의 세부 구성에 대한 내용을 설명하고, IV장에서는 모의신호와 해상실험데이터를 통해 본 논문에서 제안하는 방법의 성능을 검증한다. 마지막으로 V장에서 본 논문에 대해 결론을 맺는다.
II. 부호기 및 복호기 개요
LOFAR와 DEMON은 빔/주파수에 대한 파워 스펙트럼으로 매 프레임 별로 실수 형태의 2차원 데이터로 구성된다. 2차원 구조의 데이터에서 각 데이터 값은 다음과 같은 신호 특성을 갖는다. 첫째, 파워 스펙트럼은 대부분 노이즈 성분으로 구성된다. 일반적으로 소나에서 표적이 많이 탐지되는 상황에도 전방위에 대한 표적 개수는 수 개에 불과하다. 게다가 탐지된 표적의 광대역 신호는 S2PM, OTA[1],[2] 등의 규준화 과정을 통해 제거되기 때문에 파워 스펙트럼의 대부분은 노이즈가 되고 해당 표적의 일부 협대역 신호만 파워 스펙트럼에 남게 된다. 규준화는 신호의 광대역 성분을 제거하는 방법으로 각 주파수 빈의 파워와 인접한 빈의 파워를 비교하여, 해당 주파수 빈의 노이즈 파워를 추정하고 주파수 빈 값을 노이즈 파워에 대한 비율로 나타낸다. 이러한 방식으로 규준화를 수행하게 되면, 표적에 해당되는 빈의 값은 표적의 신호대 잡음비 형태가 되고 노이즈에 해당되는 빈의 값은 1에 근사하게 된다. 그리고 이를 다시 로그 스케일로 변환하면 노이즈는 대부분 0에 근사한 값을 갖게 된다. 정리하면 LOFAR와 DEMON의 파워 스펙트럼의 대부분은 노이즈 성분으로 구성되고, 규준화 과정 등을 통해 0에 근사한 값을 갖는 경향이 있다.
둘째, 현재 프레임의 스펙트럼은 이전 프레임의 스펙트럼과 유사한 값을 갖는다. LOFAR와 DEMON의 파워 스펙트럼을 생성하는 과정에는 빔 데이터를 주파수 도메인으로 변환하고 이를 이전 프레임의 결과와 융합하는 데이터 적분이 있다. 이는 시간에 따른 노이즈 변이를 최소화하고, 토널 탐지의 안정성을 높이기 위함으로 현재 프레임과 이전 프레임 데이터에 대한 가중치 합으로 현재 프레임의 결과를 출력하는 형태가 가장 일반적이다. 소나의 목적과 구성에 따라 적분의 형태와 적분 파라미터가 달라지나, 대부분 현재 프레임의 스펙트럼은 이전 스펙트럼의 결과는 상당히 유사한 편이며, 이는 압축에 있어서 중요한 특징 정보로 활용될 수 있다.
셋째, 파워 스펙트럼의 값은 인접 빔과 유사한 값을 갖는다. 일반적으로 선배열에 대해 빔형성을 수행하면 빔 패턴이 싱크 함수 형태로 나타나는데, 이는 인접한 빔간의 파워값이 유사함을 의미한다. 즉, 빔 별 파워는 화이트 가우시안 노이즈처럼 요동치는 값을 갖는 게 아니라 특정 패턴을 갖고 방위에 따라 변화하는 형태를 갖는다. 따라서 현재 방위의 파워가 크면 인접한 방위의 파워도 클 가능성이 높고, 그에 대한 반대도 마찬가지이다. 이러한 LOFAR와 DEMON의 특성은 부호기와 복호기를 개발하는데 있어서 주요한 단서가 될 수 있다.
Fig. 1은 본 논문에서 제안하는 부호기/복호기의 구성도이다. 부호기의 구조 및 처리 방법은 비디오 압축 코덱인 H.264[3]과 HEVC[4],[5]를 참고하였다. 프레임 별 입력 파워 스펙트럼은 자료 구조에 따라 몇 개의 매크로 블록(macro block)으로 분리되며, 매크로 블록 단위로 예측 및 보상을 수행한다. 여기서 입력 스펙트럼은 프레임 별 M개의 빔과 L개의 주파수 빈으로 구성된 M × L 크기의 데이터이며, 각 데이터 값은 규준화 후의 로그 스케일 데이터로 가정하나 로그 스케일이 아닌 데이터에도 적용이 가능하다. 또한 재생 시 화면 전시 파라미터에 대한 운용자 제어가 가능하도록 전시처리가 되지 않은 파워 스펙트럼을 가정하기 때문에 각 스펙트럼 값은 실수를 갖는다고 가정한다.
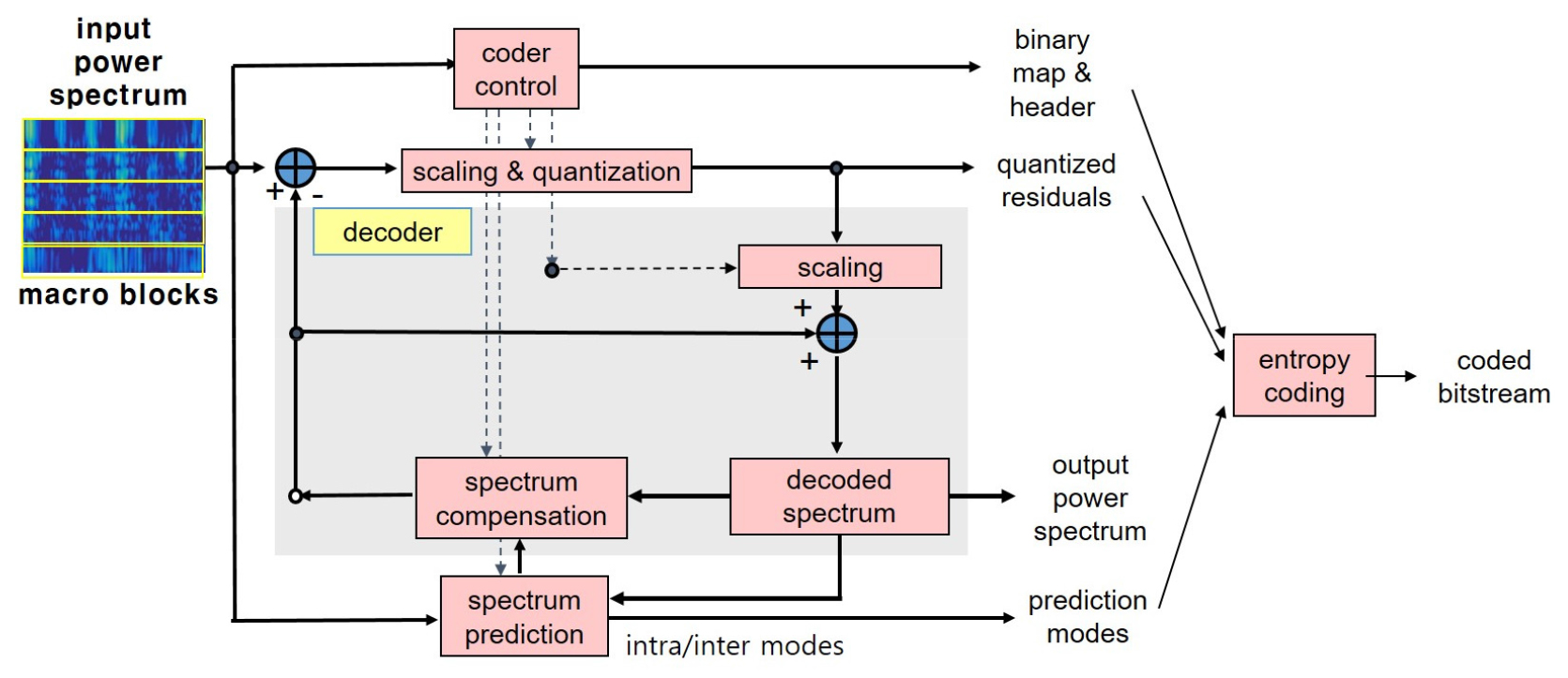
먼저 부호기는 현재 프레임의 스펙트럼에 대해 주파수 빈 별로 예측 적용 여부를 결정하는 이진맵 (binary map)을 생성한다. 이진맵을 통해 부호기는 예측 시 매크로 블록에 있는 주파수 빈 중 이진맵에서 1에 해당되는 데이터만 예측에 적용하여 예측이 필요하지 않은 데이터는 예측에서 제외하도록 한다. 그리고 부호기는 복호화된 이전 프레임 스펙트럼과 복호화된 현재 프레임의 이전 매크로 블록을 활용하여 매크로 블록 또는 서브 블록 단위로 스펙트럼 예측을 수행한다. 예측 후 복호기에서도 동일한 예측 정보로 복호화 하도록 스펙트럼 보상을 수행하며 보상에 필요한 예측 모드는 별도로 압축한다. 예측 후 부호기는 보상된 데이터와 현재 매크로 블록의 데이터의 차이를 통해 데이터의 중복성을 제거한 나머지(residual)를 획득하고 나머지는 스케일링 및 양자화 후 엔트로피 부호화된다. 최종적으로 엔트로피 부호화가 되는 데이터는 헤더 정보, 현재 프레임에 대한 이진맵, 매크로 블록 별 예측 모드, 그리고 양자화된 나머지 값이다.
복호기는 부호기의 역순으로 데이터를 복호화하며, 예측 모드를 바로 사용하기 때문에 스펙트럼 예측은 복호기에 포함되지 않는다.
III. 부호기/복호기 구성
3.1 이진맵 생성
II장에서 설명한 바와 같이 일반적인 LOFAR/DEMON 스펙트럼은 노이즈 성분이 대부분이어서 규준화 후 로그 스케일 값이 0에 근사한 값을 갖는 경우가 많으며 양자화를 통해 양자화 스텝 크기 보다 작은 값을 갖는 스펙트럼 값은 모두 0이 된다. 양자화는 해당 데이터를 정수로 변환하는 목적으로 0 ~ 의 범위에 있는 값들은 모두 0이 되고, ~ 2의 범위 값은 1이 되는 방식으로 수행된다. 따라서 양자화 이후 0의 값을 갖는 스펙트럼 값은 별도로 예측을 수행하지 않도록 하여 불필요한 나머지가 발생하지 않도록 한다. 이를 위해 양자화된 스펙트럼 값이 0인 빈은 0으로 아닌 빈은 1로 지정하는 이진맵을 생성하고 이를 예측 및 보상에서 활용한다. 복호기도 동일한 정보를 활용하도록 생성한 이진맵은 별도로 엔트로피 부호화한다.
3.2 매크로 블록 구성
파워 스펙트럼을 압축하는데 있어서 효율적인 예측 및 보상을 수행하기 위해서는 예측 단위인 매크로 블록을 지정할 필요가 있다. 매크로 블록이 세밀하게 지정되어 수개의 값만을 포함하게 되면, 예측이 정확하게 이루어져 예측 후의 나머지가 감소하나 예측을 위한 부가적인 정보가 많아 전체적인 압축에 있어서는 비효율적일 수 있으며, 이는 반대도 마찬가지이다. II장에서 설명하였던 LOFAR/DEMON 그램 특성 중 인접한 빔간의 유사성을 활용하는 측면에서 제안하는 기법은 매크로 블록을 빔 단위로 구성하였다. 예를 들어 129개의 빔과 800개의 주파수 빈으로 구성된 스펙트럼을 압축할 때 부호기는 현재 프레임에 대해 129개의 매크로 블록으로 구분하며 각 매크로 블록에는 800개의 주파수 빈에 대한 스펙트럼 값을 갖는다. 부호화 및 예측 순서는 1번 빔으로 구성된 매크로 블록부터 M번 빔의 매크로 블록 순서대로 진행한다. Fig. 2는 예측 및 보상을 위한 매크로 블록 구조를 나타낸 그림이다.

3.3 매크로 블록 예측
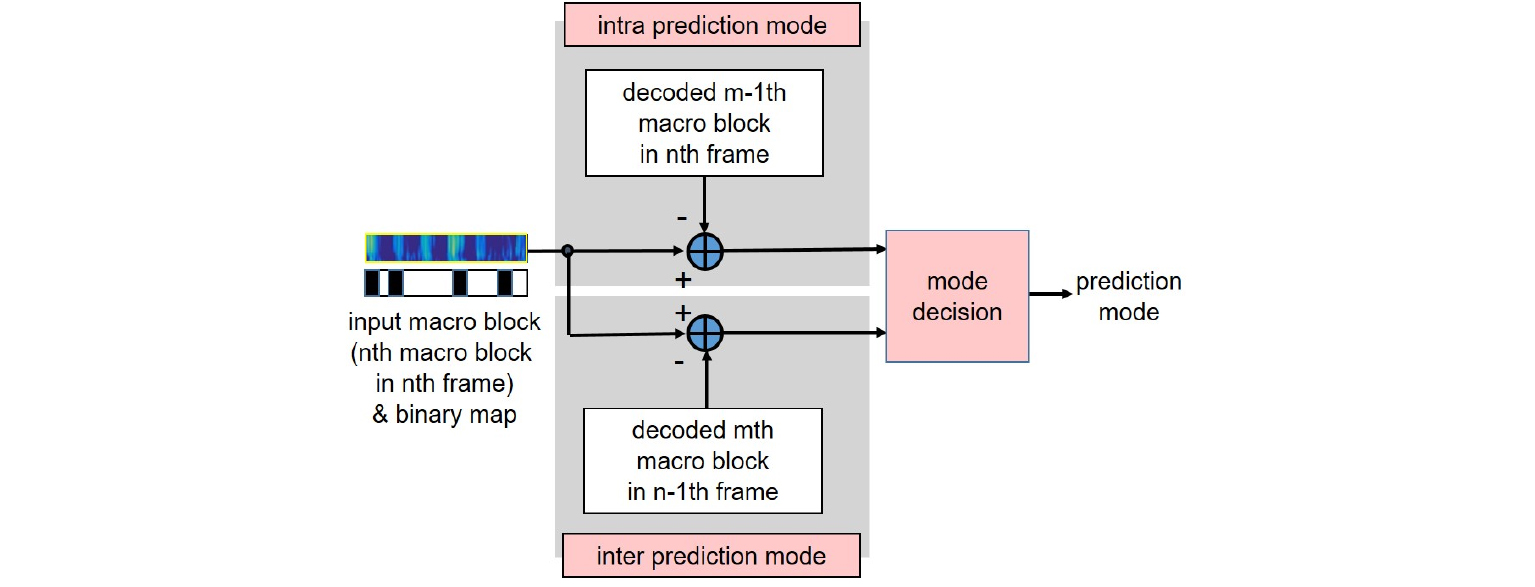
제안하는 기법은 매크로 블록 별로 예측 및 보상을 수행하며, 예측 모드로 인트라 모드(intra mode)와 인터 모드(inter mode)가 있다. 부호기는 각 모드 별 출력하는 방식으로 예측을 수행하며 예측 시 이진맵을 활용하여 맵에서 0으로 지정된 빈의 값은 예측에 사용되지 않도록 한다. 인트라 모드는 이전 프레임 정보를 활용하지 않고 프레임 내부 스펙트럼 값만 활용하는 방법으로, m번째 매크로 블록의 값을 바로 이전에 부호화/복호화된 m-1번째 매크로 블록으로 예측한다. 즉 현재 매크로 블록값들 중 이진맵이 1인 값에 대해서만 이전 매크로 블록 값을 빼서 나머지를 구하는 형태이다. 인터 모드는 이전 프레임에서 동일한 위치의 매크로 블록으로 예측하는 방법으로 인트라 모드와 같이 이진맵이 1인 값에 대해서 현재 매크로 블록과 이전 프레임의 매크로 블록의 차이를 구한다. 모드 선택(mode decision)에서는 각 모드 별로 구한 나머지 값에 대해 각각 절대치 합을 구하고 절대치 합이 작은 모드를 선택하여 이를 스펙트럼 보상 및 엔트로피 부호화에 전달한다. 즉, 예측 모드는 매크로 블록 별로 한 개의 값만 나오며, 본 예측에서는 두 개의 모드만 사용하였기 때문에 인트라 모드는 0으로 인터 모드는 1로 부호화하게 된다. 이전 프레임 정보가 없는 첫 번째 프레임 또는 이전 프레임을 사용하지 않도록 지정된 프레임의 경우에는 인트라 모드만 사용하여 예측하며 예측 모드를 별도로 부호화하지 않는다. Fig. 3은 제안하는 부호기/복호기의 스펙트럼 예측을 나타낸 그림이다.
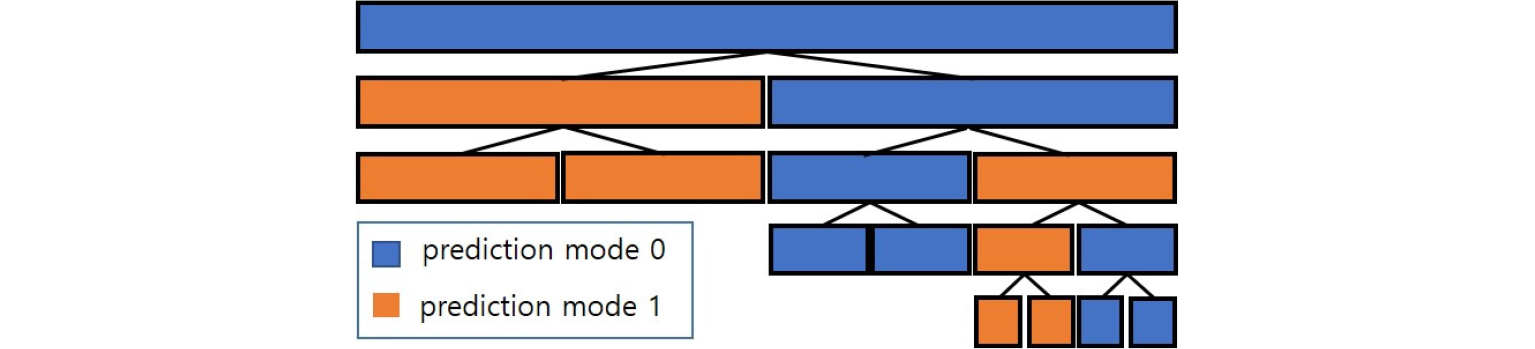
뿐만 아니라 예측의 효과를 높이기 위해 트리 형태의 매크로 블록 분할 기법을 부호기에 추가하였다. 먼저 입력 매크로 블록에 대해 매크로 블록 별 예측을 수행한다. 그리고 매크로 블록을 2개의 서브 블록으로 분할하여 각각 동일한 방식으로 예측을 수행한다. 부모 블록의 예측 모드와 두 개의 서브 블록의 예측 모드가 모두 같으면, 부모 블록의 예측 모드로 예측과 보상을 수행한다. 만약 부모 블록과 서브 블록의 모드가 1개라도 다르면 트리 구조로 해당 서브 블록을 다시 두 개로 분할하여 예측을 수행하고 부모 블록과 예측 모드를 비교하는 형태로 예측과 분할을 반복한다. 이러한 방식으로 매크로 블록을 분할하여 다양한 크기로 예측을 수행하면, 스펙트럼에 대한 중복성을 최대한으로 줄일 수 있는 최적 예측이 가능하다. 블록 사이즈가 작아질수록 예측에 대한 나머지는 줄어드는 반면, 전송해야 할 예측 모드와 블록 분할에 대한 플래그 비트는 증가하므로 최소 예측 블록 크기를 지정하여, 지나치게 블록이 분할되는 것을 방지한다. Fig. 4는 매크로 블록에 대한 예측 트리 구조를 나타낸다. 최조의 블록이 2개로 분할되고 예측 모드에 따라서 분할이 반복되는 예를 보여준다.
3.4 매크로 블록 보상
제안하는 기법의 부호기는 예측 후에 획득한 모드를 이용하여 해당 모드에 맞게 스펙트럼을 보상한다. 보상 시 적용하는 스펙트럼 데이터는 양자화 및 스케일링 등의 과정을 거친 복호화된 값으로 선정하여 복호기와 동일한 값으로 보상되도록 한다. Fig. 5는 매크로 블록 보상에 대한 간단한 예제를 보여준다. 스펙트럼 보상 이후 부호기는 현재 매크로 블록의 스펙트럼 값과 보상된 스펙트럼 값의 차이를 획득하고 이를 스케일링 및 양자화하여 엔트로피 부호화에 전달한다. 여기서 이진맵 값이 1인 주파수 빈에 대해서만 엔트로피 부호화를 수행한다.

3.5 양자화
예측한 데이터와 현재 매크로 블록의 차이를 통해 나머지를 획득하고 이를 엔트로피 부호화하여 데이터를 압축한다. 엔트로피 부호화 전 양자화를 통해 실수를 정수로 변환하며, 양자화 스텝 크기에 따라 비트율과 복호에 대한 왜곡이 결정된다. 제안하는 기법에서는 0 dB부터 200 dB까지의 범위를 16 ~ 24 비트로 양자화하도록 설정하였으며, 이 경우 최대 왜곡은 0.001526 dB ~ 0.000006 dB 정도로 화면 전시 시 차이를 확인하기 어려운 수준이다. 비록 제안하는 기법에서는 양자화로 인해 입력 데이터에 대한 손실이 발생하나, 왜곡이 미비하여 무손실 압축에 가깝다고 볼 수 있다.
3.6 엔트로피 부호화
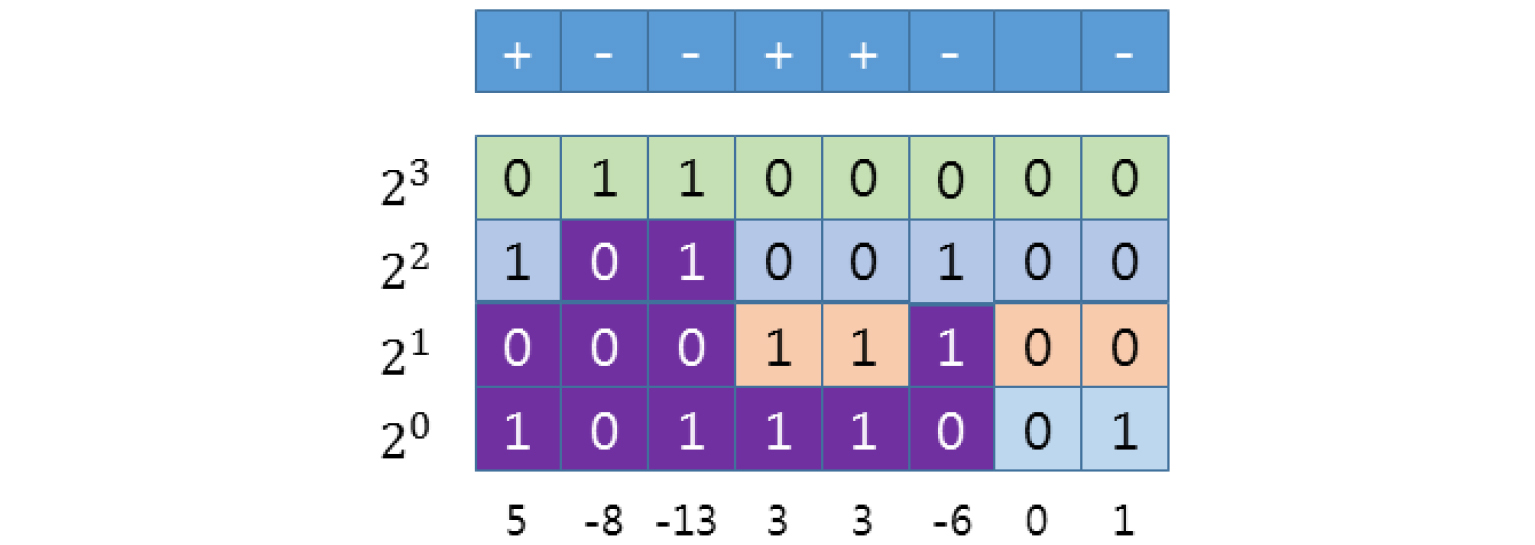
엔트로피 부호화는 일반적으로 알려진 컨텍스트 기반의 산술 부호화 기법을 사용한다.[6] 본 논문에서 엔트로피 부호화를 위한 데이터는 크게 세 가지로 프레임 별 이진맵, 예측 모드 및 분할 플래그 비트, 양자화된 나머지 값으로 구성된다. 이진맵은 프레임 별 M × L의 데이터에 대해 0과 1의 값을 갖기 때문에 독립적인 컨텍스트를 구성하여 산술 부호화 한다. 예측 모드는 예측 블록 별로 값을 갖고 본 부호기에서는 두 개의 예측 모드만 있기 때문에 예측 모드에 대한 컨텍스트로 0과 1을 산술 부호화한다. 마찬가지로 분할 여부를 알려주는 플래그 비트도 별도의 컨텍스트로 0과 1을 부호화한다. 양자화된 나머지 값은 이진맵에서 1에 해당하는 데이터에 대해서만 엔트로피 부호화하며, 최대 M × L개의 데이터가 부호화 될 수 있다. 프레임 별로 획득한 나머지 값은 다양한 크기의 값으로 구성되기 때문에 제안하는 기법에서는 비트 평면 부호화를 통해 나머지를 부호화한다.[7] 비트 평면 부호화는 부호화하려고 하는 연속된 수를 부호와 비트 평면으로 표현하고 이를 최상위 비트에서 최하위 비트 순으로 부호화하는 방법이다. 비트별 부호화 시 크게 두 개의 그룹으로 구분하여 컨텍스트를 할당하는데 각 데이터 별 첫 번째 1이 나오는 비트까지를 첫 번째 그룹으로 나머지를 두 번째 그룹으로 지정한다. 이와 같은 비트를 두 개의 그룹으로 분리하면 첫 번째 그룹에서 0이 대부분이고 두 번째 그룹에서는 0과 1이 유사한 비율로 나타나기 때문에 엔트로피 관점에서 추가적인 비트 할당 없이 압축률을 높일 수 있게 한다. Fig. 6은 비트 평면 부호화에 대한 예로써 5, –8, –13.. 등의 수에 대한 비트 평면과 엔트로피 부호화 시의 컨텍스트를 색으로 나타낸다. 부호기는 최상위 비트에 대해 개별 컨텍스트로 부호화한다. 여기서 –8과 –13은 최상위 비트 레벨에서 1이 나왔기 때문에 –8과 –13의 나머지 비트에 대해서는 별도의 컨텍스트를 할당한다. 그 다음 비트 레벨에서 –8과 –13에 해당되는 비트를 제외한 나머지 비트에 대해 또 다른 컨텍스트로 부호화하고 –8과 –13에 대한 비트는 비트 레벨과 무관한 공통 컨텍스트로 부호화한다. 첫 번째 1이 나온 수에 대해서는 해당 수의 부호(+,–)를 부호에 대한 컨텍스트로 부호화 한다. 이와 같은 방법으로 컨텍스트를 구성하고 비트를 압축하게 되면, 0에 해당되는 값을 부호화할 때는 부호를 별도로 부호화하지 않게 된다. 그리고 공통 컨텍스트를 제외한 나머지의 컨텍스트에는 대부분 0의 데이터만 몰려있게 되어 산술 부호기의 성능을 극대화시킬 수 있다.
3.7 복호기
복호기에서는 부호기에서 진행한 순서의 역순으로 데이터를 복원하며, 엔트로피 복호화 이후 나머지를 스케일링하고 이를 보상된 값과 합하여 현재 매크로 블록에 대해 복호화를 수행한다. 부호기의 예측 및 보상에서 복호화된 스펙트럼 값을 사용하기 때문에 복호기에서는 동일한 데이터를 통해 파워 스펙트럼을 복원하게 된다.
IV. 실험 결과
본 장에서는 제안하는 LOFAR/DEMON 그램 압축 성능을 확인하기 위한 실험 결과를 제시한다. 실험에 대한 신뢰도를 높이기 위해 모의 신호 시뮬레이션을 통해 취득한 LOFAR와 실제 해상에서 취득한 LOFAR를 사용하였다.
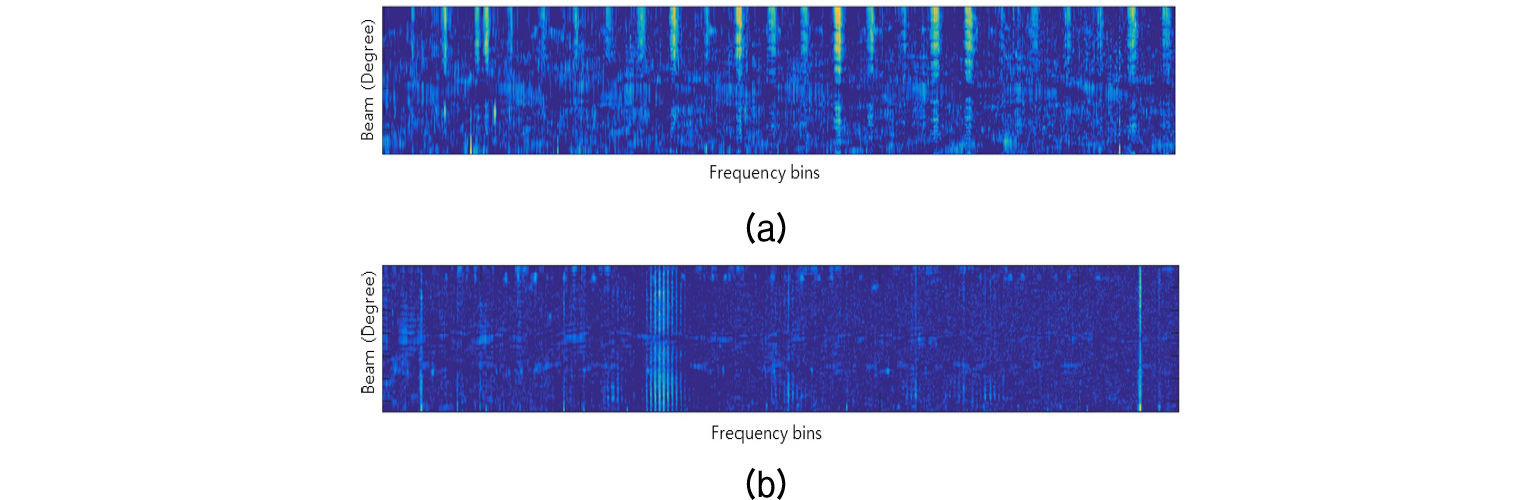
모의 신호 시뮬레이션을 위해 백색 잡음 환경에서 기동하는 임의의 협대역 표적 신호를 센서 별로 생성하였고, 생성된 모의 신호에 대해 빔형성 및 LOFAR 처리를 수행하여 LOFAR 데이터를 획득하였다. 해상 데이터는 실제 표적이 많은 해상에서 선배열로 획득한 신호에 동일한 처리를 수행한 데이터이다. 데이터에 대한 세부 내용은 Table 1에 나타내었다. Fig. 7은 3번과 4번 데이터에 대한 특정 프레임에서의 FRAZ를 나타낸다. 그림에서 확인할 수 있듯이, 실제 해상 데이터에는 다양한 형태의 잡음과, 협대역 표적으로 보이는 일부 토널들이 존재한다.
Table 1. Properties of test data.
제안하는 기법의 성능을 객관적으로 비교하기 위해, 유사 압축 기법과의 비교가 필요하나, LOFAR 또는 DEMON 그램에 특화된 압축기법이 없어서 일반적인 데이터 압축 기법인 7zip 기법[8]과 성능을 비교하였다. Table 2는 Table 1에서 명시한 4개의 데이터에 대해 기존 기법과 제안 기법의 압축률을 나타낸다. 7zip 기법은 무손실 압축이고 LOFAR/DEMON에 특화된 기법이 아니다보니 대략 1.4 ~ 1.7 정도의 압축률을 보인다. 반면 제안 기법은 16비트 양자화 경우 8 ~ 9의 높은 압축률을 보이며, 무손실 압축에 가까운 24비트 양자화에서도 4 ~ 6정도의 압축률을 보여준다. 뿐만 아니라 제안하는 기법이 실제 시스템에 적용가능한 지 확인하기 위해 부호기의 연산 속도를 Table 2에 나타내었다. 연산 시간은 인텔 i7-6700 3.4 GHz 프로세서가 탑재된 PC를 이용하여 측정하였다. 연산 속도는 양자화 비트에 따라 다르나 최소 초당 9 프레임 처리 가능한 것으로 보이며, 이는 1 프레임 기준으로 약 0.11 s에 해당되므로, 실시간 처리가 충분할 것으로 판단된다.
Table 2. Compression ratios.
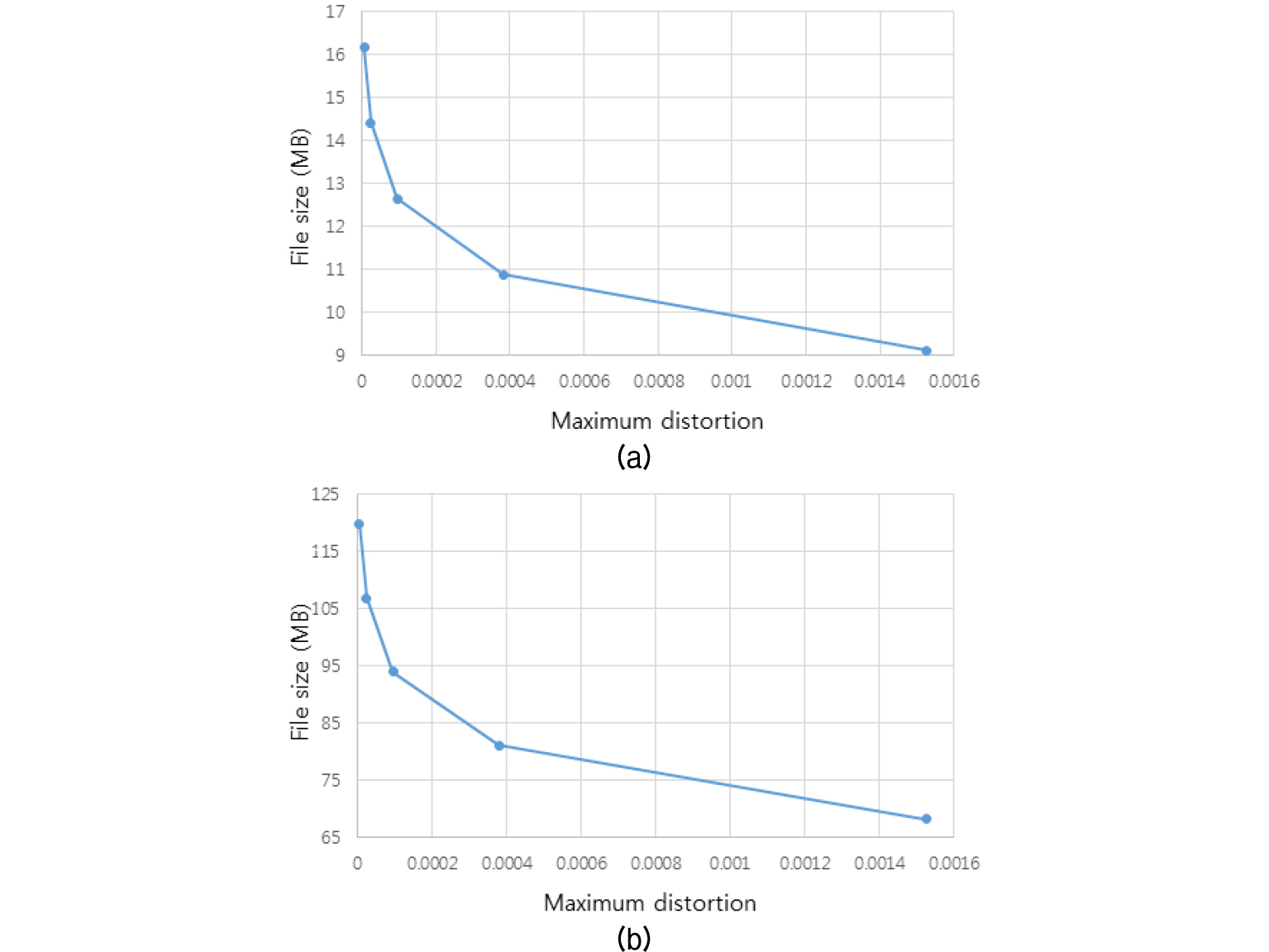
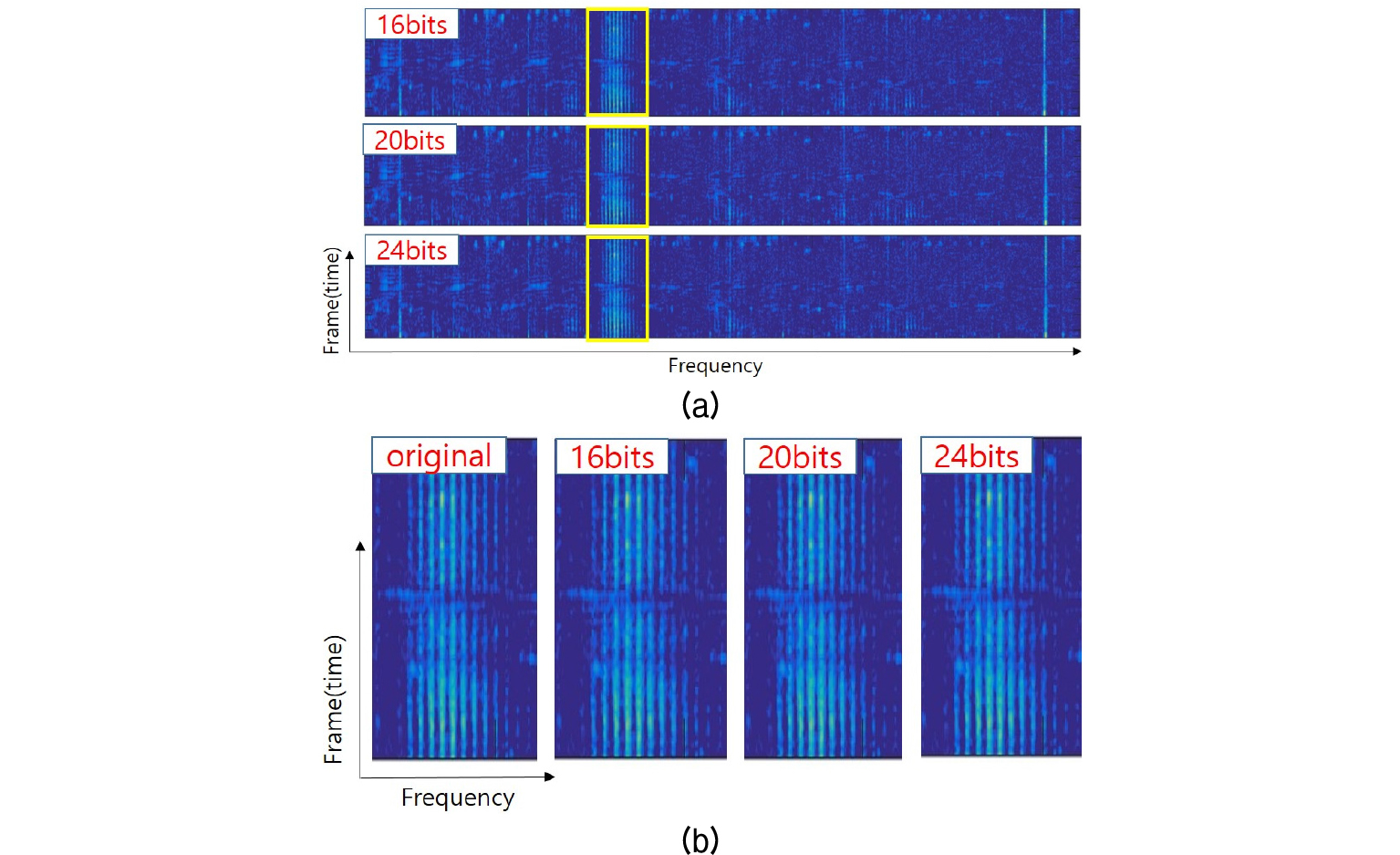
제안하는 기법은 손실 압축으로 양자화 파라미터에 따라서 비트율과 왜곡이 달라진다. 이는 압축률에 대 한 조정이 가능함을 의미한다. 이를 확인하기 위해 Fig. 8에서 1번, 4번 데이터에 대한 비트율-왜곡 커브를 나타내었고, 왜곡의 정도를 시각적으로 확인하기 위해 4번 데이터에 대한 복호화된 결과를 Fig. 9에 나타내었다. 그림을 통해 확인할 수 있듯이 복호화된 데이터에서 양자화 에러에 대한 차이를 확인하기는 어려우며, 가장 높은 압축률을 보이는 16비트 양자화 복원 결과에서도 정보손실은 미비한 수준이다. 제안하는 압축 기법의 성능은 양자화 파라미터에 따라 압축률과 복원 데이터 왜곡간의 트레이드 오프 특성을 보이나, 16비트 이상의 양자화 파라미터에서는 왜곡이 거의 없는 결과를 도출하므로, 실용적인 관점에서 제안 기법의 성능은 8 ~ 9의 압축률을 갖는다고 할 수 있다.
V. 결 론
본 논문에서는 LOFAR/DEMON의 그램을 압축하는 기법을 제안하였다. LOFAR/DEMON 그램은 고유의 특성을 갖고 있어, 효율적인 압축을 위해서 토널 및 규준화 등으로 발생한 특성을 활용하였다. 제안한 부호기 및 복호기는 이진맵 생성, 예측, 보상, 양자화, 엔트로피 부호화 등으로 구성되어 있으며, 실험 결과를 통해 제안하는 기법의 성능을 확인하였다. 제안하는 기법은 양자화 비트에 따라 압축률이 다르지만, 데이터의 손실이 거의 없는 16비트 양자화 기준으로 약 1/9 크기로 데이터 량을 줄일 수 있다. 뿐만 아니라 데이터 손실을 감안한 8비트 양자화의 경우에는 1/34비율로 압축하는 것도 가능하다. 이는 데이터의 저장 용량이 부족하거나 데이터 전송 시 대역폭이 부족한 무선 통신 환경에서 효과적으로 활용될 수 있을 것이다.
