

I. 서 론
수면은 휴식과 회복 과정으로 몸과 마음의 건강을 위해 필요할 뿐만 아니라 삶의 질을 향상하고 질병을 예방하는데 중요한 요소이다. 코골이는 수면 중 호흡 과정에서 발생하는 공기의 흐름이 좁아진 기도를 통과하면서 연구개와 목젖 등의 주위 구조물에 진동을 일으키는 것을 말하며 수면을 방해하는 대표적인 수면장애 증상으로 알려져 있다. 코골이는 심할 경우 수면 중 호흡이 반복적으로 멈추는 수면 무호흡증을 유발하며 피로감, 심혈관 질환, 갑작스러운 무호흡과 같은 증상을 발생시킨다.[1]따라서 코골이는 수면을 방해할 뿐만 아니라 생명에 지장을 줄 수 있는 합병증을 유발하기 때문에 증상 개선을 위한 진단이 중요하며 최근 기계학습 방식을 이용한 코골이 식별 연구들이 진행되고 있다.
기존의 연구 중 신경망 기반의 코골이 식별 알고리즘 연구[2]에서는 주파수 차감 방법을 이용하여 잡음을 제거하고 소리 발생 구간을 검출한 후 음형 주파수와 캡스트럼 계수를 오류 역전파 알고리즘에 적용하여 코골이를 식별하였다. 또한, 스마트 베개를 위한 스펙트럼 특징과 코골이 판별 방법 연구[3]에서는 음원의 샘플링 율을 낮춘 후 고속 푸리에 변환한 결과에 1차 미분과 2차 미분을 적용하여 추출한 특정 주파수 대역의 특징을 SVM(Support Vector Machine)에 적용하여 코골이를 검출하였다.
이처럼 기존의 코골이 식별 연구들은 데이터로부터 멜 주파수 캡스트럼 계수와 같은 주파수 특징을 추출하고 이를 기계 학습 방식의 SVM[3], 가우시안 혼합 모델(Gaussian Mixture Model, GMM)[4]에 적용하여 학습하고 식별하였다. 최근에는 영상분류 분야에 효과적으로 적용되고 있는 합성 곱 신경망(Convol- utional Neural Network, CNN)이 다양한 소리식별 분야에 적용되고 있으며 소리 특징을 보다 효과적으로 추출하기 위해서 신경망의 깊이가 깊어지게 되었다.[5] 하지만 신경망의 깊이가 깊어지면서 매개변수의 숫자가 많아졌고 계산량이 많아지는 문제와 함께 기울기의 소실/폭발 문제가 발생하여 오히려 성능이 하락하게 되었다. 이에 깊어지는 신경망의 문제를 해결하기 위한 방안으로 잔류 학습 방식이 제안되었다. 잔류 학습 방식은 특정 층에 잔류 연결을 추가하는 방식으로 계산량의 증가와 기울기의 소실/폭발 문제를 효과적으로 해결함으로써 깊은 신경망 구조에서도 우수한 성능을 보여준다.[6]
이에 본 논문에서는 CNN과 잔류 학습 방식을 결합한 잔류 합성 곱 신경망(Residual CNN)을 적용하여 코골이를 식별하는 방식에 대해 제안한다.
본 논문의 구성은 다음과 같다. II장에서는 제안하는 코골이 식별 방식의 구조에 관해 설명한다. III장에서는 실험을 통한 Residual CNN 기반의 코골이 식별 결과를 제시하고 IV장에서는 결론을 맺는다.
II. 코골이 식별 방식의 구조
Fig. 1은 본 논문에서 제안한 코골이 식별 방식의 전체 과정을 보여준다.
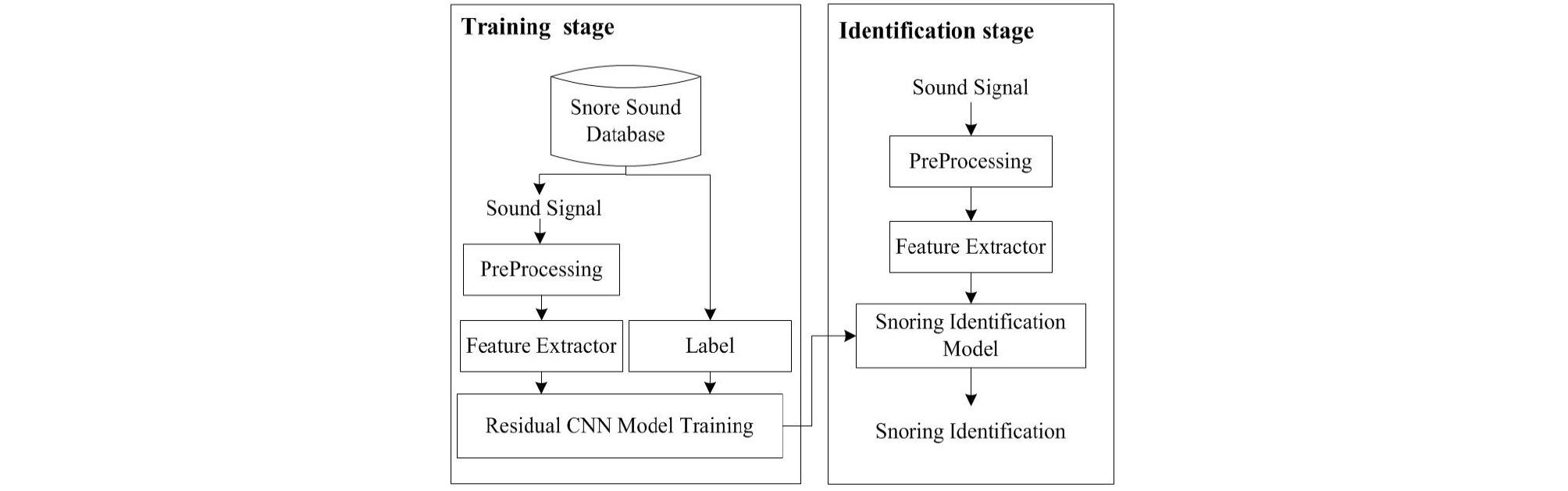
제안하는 방식은 학습단계와 식별단계로 구분된다. 먼저, 학습단계에서 입력된 소리는 전처리 과정을 통해 소리 발생 구간으로 검출된다. 소리 발생 구간은 특징 추출부를 통하여 스펙트로그램으로 변환되고 잔류 합성 곱 신경망에 적용되어 코골이 식별 모델을 생성한다. 식별단계에서 새로운 소리가 입력되면 전처리 과정을 통해 소리 구간을 검출하고 특징 추출부를 통해 스펙트로그램으로 변환한다. 스펙트로그램은 학습단계에서 생성된 코골이 식별 모델에 입력되어 코골이 발생 여부가 식별된다.
2.1 전처리 과정
전처리 과정에서는 입력된 소리의 소리 활성 여부를 판별하여 소리 발생 구간을 검출한다.[7] 이를 위해 먼저, 입력된 소리를 2 ms(16 samples)의 프레임 단위로 분할한다. 그리고 소리의 활성 여부를 판단하기 위해 분할된 소리의 에너지를 계산하고 소리의 에너지와 자기 상관 분산도(Autocorrelation Vector Variance, AVV)를 계산한다. n번째 소리의 에너지와 AVV는 다음과 같이 계산한다.
| $$\begin{array}{l}E(n)=\sum_{k=1}^NE_k(n),\\\\E_k(n)=\sum_{i=16(k-1)+1}^{16k}x^2(i),\end{array}$$ | (1) |
| $$\rho (n)= \frac{\sum _{k=1} ^{N} (E _{k} (n)-E(n)/N) ^{2}} {N},$$ | (2) |
여기서 N, k, i는 분할된 소리의 개수, 분할된 소리의 번호, 시간 변수를 말하며, 는 이산 소리를 말한다. 또한, 과 은 n번째 소리와 k번째 분할된 소리의 에너지를 말한다. 그리고 Eq. (2)에서 은 소리의 에너지 분산 값으로 AVV를 나타낸다.
다음으로 입력된 소리로부터 계산된 에너지와 AVV를 초기 설정된 에너지, AVV의 문턱값과 비교한다. 이때, 초기 문턱값은 데이터베이스로부터 무작위로 선택한 소리 3초 동안의 평균 에너지와 평균 AVV로 설정하였다. 에너지와 AVV의 값이 각 문턱값보다 작은 경우 해당 소리를 잡음 및 무음 구간으로 판별하고, 나머지 경우 소리 발생 구간으로 검출한다. 또한, 본 논문에서는 잡음 상황의 변화를 파악하여 문턱값을 갱신시킴으로써 높은 정확도로 소리 발생 구간을 검출한다. 잡음 상황의 변화를 파악하기 위해 n번째 소리가 잡음으로 판별될 경우 이를 기반으로 잡음 신호 전체의 평균 에너지와 평균 AVV를 계산한다. 그리고 계산된 평균 에너지와 평균 AVV를 n-1번째 소리를 기반으로 계산된 잡음 신호 전체의 평균 에너지와 평균 AVV와 비교하여 잡음 상황의 변화를 파악하고 문턱값을 갱신한다. 하지만 n번째 소리가 소리 발생 구간으로 검출될 경우 에너지와 AVV의 문턱값을 이전의 문턱값으로 유지한다.[8]
2.2 특징 추출부
특징 추출부는 소리를 시간 축과 주파수 축의 변화에 따른 진폭의 차이를 시각적으로 표현한 스펙트로그램으로 변환한다. 특징 추출부에 입력된 소리는 16 ms의 해밍 창이 8 ms씩 중첩되어 프레임 단위로 분할되고 단시간 푸리에 변환되어 128-bin 스펙트로그램으로 출력된다.
본 논문에서는 코골이 식별을 위한 네 가지의 소리 종류로써 일반인의 수면 시 발생하는 호흡음, 숨을 쉴 때 좁아진 기관지를 따라 공기가 통과할 때 들리는 특징적인 호흡음으로 쌕쌕거림과 같은 천명음, 수면 시 코골이 환자에게 생기는 코골이, 수면 시 뒤척일 때 발생하는 이불 소리를 사용하였다.
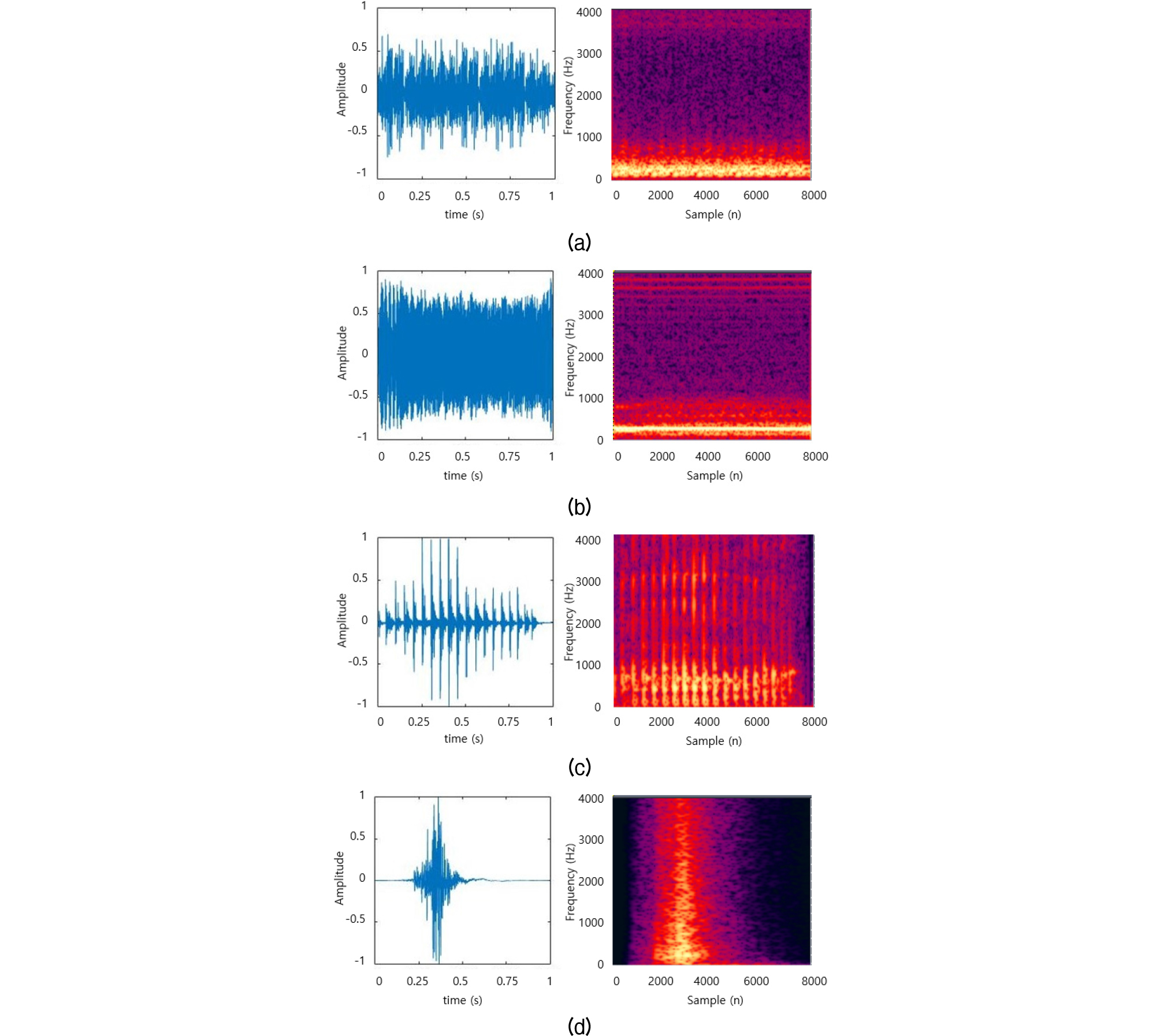
Fig. 2는 각 소리 종류의 대표적인 소리 파형과 각 소리 파형을 변환한 스펙트로그램으로 신경망이 각 소리의 에너지 분포 특징을 통해 소리의 종류를 식별할 수 있는지 확인하고자 한다. Fig. 2(a)는 호흡음의 스펙트로그램으로 호흡음은 주로 고조파 성분으로 구성되어 있으며 대부분의 호흡음은 150 Hz ~ 400 Hz의 저주파 영역에 집중적으로 에너지가 분포된 모습을 보인다. Fig. 2(b)는 천명음의 스펙트로그램으로 호흡음과 같이 주로 고조파 성분으로 구성되어 있으며 시간 축을 따라 에너지가 분포된 모습을 보인다. 하지만 천명음은 호흡음과 달리 200 Hz ~ 350 Hz의 주파수 영역에 에너지가 분포되어 있는 경향을 보이며 주파수 대역폭이 좁게 나타난다. Fig. 2(c)는 코골이의 스펙트로그램을 나타낸다. 코골이는 주로 타악기 성분으로 특정 시각에서 에너지가 발생하고 주파수 축의 방향을 따라 에너지가 집중되어 있어 호흡음, 천명음과 축의 방향에 따른 에너지 분포 차이가 나타난다. 또한, 코골이는 대부분 50 Hz ~ 1000 Hz와 2,600 Hz ~ 3,600 Hz의 주파수 영역에서 정점이 나타나고 시간 축을 따라 규칙적으로 에너지가 발생하는 모습을 보인다. Fig. 2(d)는 이불 소리의 스펙트로그램으로 코골이와 마찬가지로 타악기 성분으로 구성되기 때문에 주파수 축을 따라 에너지가 분포되어 있지만, 코골이와는 달리 에너지가 규칙적으로 발생하지 않고 고주파 영역으로 갈수록 강도가 감소한다.[5]
2.3 코골이 식별 부
본 논문에서는 코골이 식별을 위한 신경망으로 Residual CNN을 제안한다. 제안하는 Residual CNN은 CNN에 잔류 학습 방식을 결합한 구조로 특정 층에 입력과 출력을 연결하는 잔류 연결을 추가하여 입력 마디에 존재하는 정보들을 다음 마디에 직접 전달한다. 이는 깊은 심층망의 기울기의 소실/폭발 문제를 효과적으로 해결하고 연산을 간단하게 진행하여 성능 저하의 문제를 해결한다.[9]
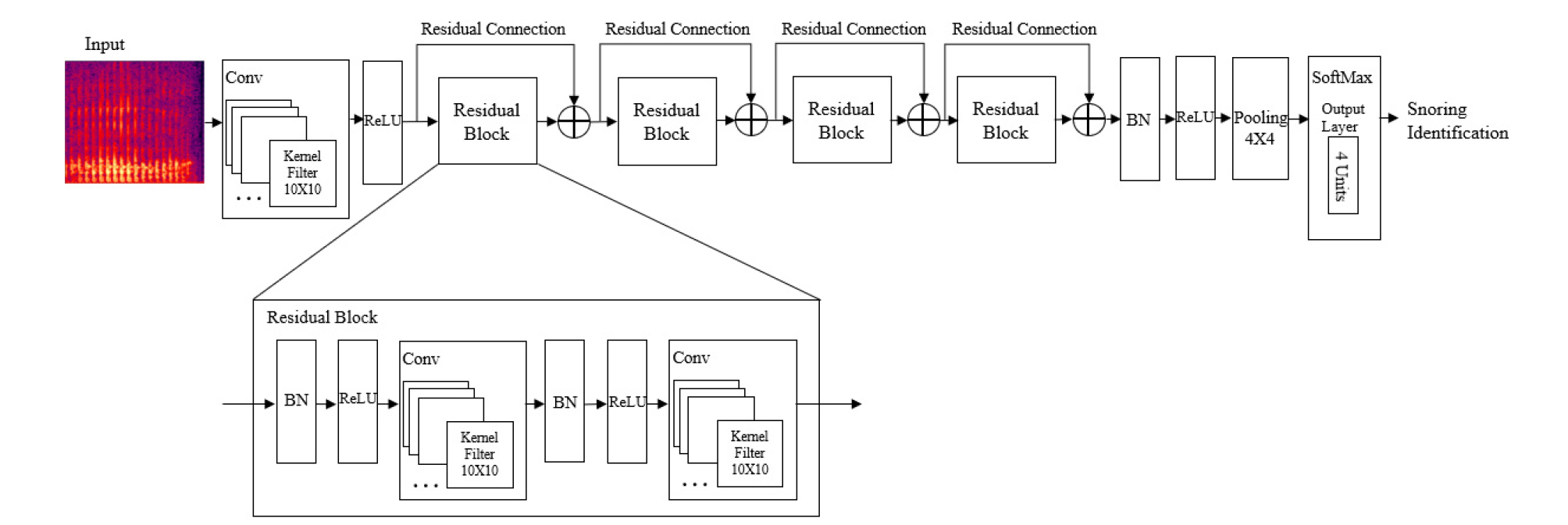
Fig. 3은 본 논문에서 제안하는 Residual CNN 구조도를 보여준다. 먼저 Residual CNN에는 입력 소리를 변환한 128 × 61 크기의 스펙트로그램이 입력된다. Residual CNN은 3가지 형태의 층으로 구성되며 각각 합성 곱 필터(Convolutional filter, Conv), 선형 유닛 활성 함수(Rectified Linear Units, ReLU)로 구성된 첫 번째 층과 4개의 잔류 블록으로 구성된 두 번째 층, 일괄 정규화(Batch Normalization, BN), ReLU, Pooling, Softmax로 구성된 세 번째 층으로 이루어진다. 첫 번째 층의 Conv에서는 10 × 10 크기를 가진 커널 필터 16개를 통해 16개의 특징 맵이 추출된다. 추출된 특징 맵은 ReLU를 통해 음수는 0으로 양수는 그대로 출력되며 BN을 통해 정규화된다. 두 번째 층의 잔류 블록은 BN, ReLU, Conv가 2번 반복되는 구조로 입력 데이터의 정보를 훼손시키지 않기 위해 잔류 연결에는 어떠한 연산 과정도 추가하지 않았다. 이를 식으로 표현하면 다음과 같다.
| $$y_l=x_l+F(x_l,W_l,b_l),$$ | (3) |
여기서 F는 잔류 블록의 연산 과정을 나타내며, 와 은 각각 l번째 잔류 블록의 가중치 행렬과 편향 행렬을 말한다. 또한, 은 입력 데이터, 은 출력 데이터를 나타낸다. 이때, l + 1번째 잔류 블록의 입력 데이터 을 라 하고 여러 잔류 블록에 대한 입력과 출력을 식으로 표현하면 다음과 같다.
| $$y _{L} =x _{l} + \sum _{i=l} ^{L} F(x _{i} ,W _{i} ,b _{i} ),$$ | (4) |
여기서 L은 l보다 깊은 층을 말하며 L이 l보다 깊은 곳에 있을 경우 성립한다. 이는 L번째 잔류 블록의 출력 데이터 이 l번째 잔류 블록의 입력 데이터 과 잔류 블록의 연산 과정 F의 합들로 이루어진다는 것을 보여주며 상위층의 기울기 값이 변하지 않고 그대로 전달되어 기울기의 소실/폭발 문제를 효과적으로 해결한다는 것을 보여준다. 본 논문에서는 4개의 잔류 블록을 사용하였으며 각 잔류 블록의 Conv는 10 × 10 크기의 커널 필터 32개를 사용하였다. 세 번째 층에서는 BN과 ReLU를 통해 앞선 과정에서 추출된 특징 맵을 정규화한다. 그 다음, 4 × 4 크기를 가진 Pooling 과정을 통해 특징 맵의 평균을 구하고 Softmax를 통해 4개의 소리 종류에 각각 해당할 확률로 계산하여 가장 높은 확률에 해당하는 소리 종류를 예측 결과로 출력한다. 또한, 역전파 과정에서 최적화를 위한 비용 함수로 Cross entropy를 사용하여 오차를 구하고[9]Adam optimizer를 사용하여 가중치를 갱신함으로써 오차를 최소화하였다.[6]
본 논문에서 제안한 잔류 합성 곱 신경망은 잔류 학습 방식을 통해 깊은 신경망 구조로 인한 성능 저하 문제를 해결한다. 또한, 잔류 학습 방식과 함께 각 잔류 블록의 앞부분에 BN을 배치함으로써 정규화 효과를 얻을 수 있으며 최적화가 쉬워지고 안정된 학습으로 과적합을 방지하는 장점을 가진다.[6]
III. 실 험
3.1 실험 데이터
본 논문에서는 코골이 식별을 위해 호흡음, 천명음, 이불 소리, 코골이로 구성된 네 가지의 소리 종류를 선정하였다. 각 소리 종류의 데이터는 피험자의 동의하에 피험자가 자는 동안 디지털 마이크를 사용하여 16 bit 해상도와 8 kHz의 샘플링 율로 녹음되었고 피험자의 성별과 상태에 따른 특성을 반영하지 않았다.
본 논문에서는 코골이 200개, 호흡음 42개, 천명음 55개, 이불 소리 80개로 전체 377개의 소리를 실험에 사용하였으며 성능 측정을 위해 4-fold 교차 검증 방법을 적용하였다. 4-fold 교차 검증 방법은 전체 데이터를 4개의 fold로 분할한 후 각 fold를 식별 데이터로, 나머지 3개의 fold는 학습 데이터로 선정하여 4번의 실험을 진행한다. 여기서, 각 fold에 속한 소리 종류의 비율을 동일하게 설정하고 4-fold로 설정하였을 때 남은 데이터는 사용하지 않았다. 실험은 각 fold에 대해 전체 데이터 중 제대로 식별된 데이터 비율인 정확도를 측정하고 평균치를 구하여 전체 구조의 성능을 평가한다. 본 실험에서는 4-fold 교차 검증 방식을 이용하여 모든 데이터를 학습단계에도 적용하고 식별단계에도 적용함으로써 전체 데이터에 대한 공정한 실험을 수행하였다.
3.2 실험 결과
본 논문에서 제안하는 Residual CNN을 검증하기 위해 k-최근접 이웃 알고리즘(k-Nearest Neighbor, k- NN)과 GMM, CNN의 실험을 진행하여 결과를 비교하였다. 먼저, k-NN은 특정 공간 내에서 입력과 제일 유사한 k개 요소의 소리 종류를 통해 입력의 소리 종류를 식별하는 방식으로 본 실험에서는 입력과 요소들의 유사도를 계산하기 위해 비교적 단순한 유클리디안 거리 함수를 적용하고 k-NN의 초 매개변수 k의 값을 홀수인 3, 5, 7을 선택하여 실험하였다. GMM은 여러 개의 가우스 분포 함수를 통해 확률 분포 모델을 추정하여 식별하는 기계학습 방식으로 본 실험에서는 가우시안 구성요소를 4로 설정하고 통계적 분포를 선형 결합 하는 방법으로 최적화를 위해 기댓값 최대화(Expectation-Maximization, EM) 알고리즘을 사용하였다. 또한, 가우시안 분포를 표현하기 위한 평균 벡터, 공분산 행렬, 사전 행렬의 초깃값은 0으로 설정하고 EM 알고리즘의 반복 횟수는 100번, 오차 허용 범위 값은 0.001로 설정하였다. 여기서 k-NN과 GMM의 입력값으로는 소리 신호로부터 추출한 13차의 멜 주파수 켑스트럼 계수를 사용하였다.[10] CNN은 제안하는 Residual CNN과의 비교를 위해 10 × 10 크기의 커널 필터 32개로 구성된 Conv 9개와 2 × 2 크기의 Pooling 2개를 사용하였고 512개의 뉴런을 가진 Fully Connected Layer와 Softmax를 사용하였다.
Table 1은 본 논문에서 진행한 실험의 결과를 나타낸다. 기계학습 방식의 k-NN은 k의 값이 3일 때 가장 높은 91.8 %의 정확도로 코골이를 식별하였고 GMM은 92.6 %의 정확도를 보였다. 반면 신경망 구조의 CNN은 GMM보다 높은 96.8 %의 정확도로 코골이를 식별하였으며 제안하는 Residual CNN은 97.8 %로 가장 높은 정확도를 보였다. 본 논문의 실험 결과를 통해 소리의 스펙트로그램 안에 존재하는 특징을 추출하여 학습을 진행하는 CNN이 기존의 k-NN, GMM보다 효과적이며 본 논문에서 제안하는 Residual CNN이 가장 높은 정확도로 코골이를 식별함을 알 수 있다. 또한, 본 논문에서는 학습 성능을 평가하기 위해 학습 데이터를 학습단계와 식별단계에 동일하게 적용한 자가 테스트 실험을 진행하였다. 실험 결과 Residual CNN과 CNN은 각각 99.2 %와 98.4 %의 결과를 보이며 Residual CNN이 CNN보다 0.8 % 더 높게 나타났다. 그리고 CNN의 일반 테스트의 결과는 자가 테스트 결과로부터 1.6 % 하락했지만 Residual CNN의 결과는 1.4 % 하락하였다. 이를 통해 제안하는 Residual CNN이 안정된 학습을 통해 모델을 생성함으로써 과적합을 방지하고 우수한 성능으로 코골이를 식별함을 확인할 수 있다.
Table 1. Result of snoring identification.
| Method | Accuracy | Training accuracy |
| k-NN | 91.8 % | 93.9 % |
| GMM | 92.6 % | 94.5 % |
| CNN | 96.8 % | 98.4 % |
| Residual CNN | 97.8 % | 99.2 % |
IV. 결 론
본 논문에서는 잔류 합성 곱 신경망을 이용하여 수면장애 증상인 코골이 식별 방식을 제안하였다. 제안한 방식은 전처리 과정을 통해 소리 발생 구간을 검출하고 검출된 소리 발생 구간은 특징 추출부를 통해 스펙트로그램으로 변환되어 잔류 합성 곱 신경망을 통해 코골이를 식별한다.
실험을 통해 제안한 방식과 기존의 방식을 비교한 결과 본 논문에서 제안한 방식이 가장 우수한 성능을 보여주었다. 향후 피험자의 성별/상태를 고려한 코골이 데이터를 통해 코골이 식별 모델을 생성하고 코골이 뿐 아니라 다양한 생체 신호를 통한 질병 식별 방법에 대해 연구할 계획이다.
