

I. 서 론
수상 및 수중 플랫폼에서 능동소나 및 관련 신호처리 기술이 도약적으로 발전하고 있지만, 여전히 수동소나의 효용성은 중요한 위치를 차지하고 있다. 특히, 수중 플랫폼의 경우에는 능동소나 운용에 제한을 받기 때문에 수동소나를 활용한 수상 및 수중 관심표적 탐지 및 추적이 더욱 중요하다. 그러나, 계절 및 시간에 따라 해양환경이 두드러지게 변화하고 음파전달특성에 영향을 많이 주는 해역에서는 운용자가 관심표적 외의 신호, 클러터가 많이 발생하며 관심표적을 구별하는 데에 어려움이 있다.
특히, 관심표적 및 다수의 클러터 발생 시에 운용자는 해당 방사소음에 추적을 초기화, 즉 개시 및 해당 추적표적에 대해 분석하며, 이에 따라 운용자의 운용 업무가 과중된다.
주파수선을 추적하는 협대역추적에서 표적추적을 개시하는 방법으로는 대표적으로 2가지 방법이 있다. 운용자가 관심표적에 직접 표적추적을 초기화 또는 개시하는 방법과 더불어 표적추적 자동개시 알고리즘을 활용하여 표적으로 판별되는 신호에 대해 표적추적을 개시하는 방법이다. Table 1과 같이 표적추적 개시 방법에 따라 장단점은 존재하며, 특히, 자동초기화 방법은 해양환경변화가 복잡하고, 이로 인해 표적으로 오인식할 수 있는 클러터가 많이 발생하는 대한민국 해역에서는 활용이 지양되는 방법이다.
Table 1.
Comparison between operator initiated and automatic initiated.
Table 1에서 알 수 있듯이 표적추적 자동개시 방법은 클러터를 표적으로 오인식하여 추적 개시를 하는 단점을 보완한다면, 대한민국 해역특성 상 다수의 표적에 대한 추적개시관리에 많은 이점이 있다.
이에 대한 해결책으로 견실한 협대역표적 추적자동개시 알고리즘 및 자동추적 알고리즘[1,2,3,4]이 제안되고, 해상 플랫폼에 적용되어 왔다. 표적추적 자동개시를 위한 초기값 설정을 위해 샘플링 시간에 따른 측정치의 방위 및 방위변화율 또는 주파수 및 주파수 변화율을 활용하는 기법 제안[5] 및 성능비교[6]가 실시되었다. 견실한 표적 자동 개시 및 자동 추적을 위해서는 응용분야에 따라 적용하는 자료결합 기법이 중요한 역할을 수행하며, 자동 개시 및 자동 추적 절차 내에서 target confirmation 이전에 자동 개시를 위한 초기값 설정을 기반으로 내부추적을 실시한다. 이러한 자동 개시 및 추적 절차 내의 내부추적을 위한 자료결합 방법으로 다음과 같은 다양한 연계 기법이 제안되었다.
필터의 예측값과 예측값을 기준으로 연계 게이트 내에서 가장 가까이 위치하는 측정치를 연계하는 Nearest Neighbor association Filter(NNF)[7]와 회귀적인 NNF에 확률 개념을 적용한 Probabilistic Nearest Neighbor association Filter(PNNF)[8]가 제안 및 폭넓게 적용되어 왔다. 이와 함께 필터의 예측값을 기준으로 연계 게이트 내에서 신호준위가 가장 큰 측정치를 연계하는 Strongest Neighbor association Filter(SNF)[9]와 PNNF와 동일한 관점에서 접근한 Probabilistic Strongest Neighbor association Filter(PSNF)[10]가 다른 대안으로 적용되었다.
또한, PNNF 및 PSNF에 대비하며 표적추적 자동개시 및 자동추적의 견실성을 향상시키기 위해 연계 게이트 내에서 추출한 모든 측정치의 정보에 가중치를 적용하여 활용하는 Probabilistic Data Association Filter(PDAF)[11]가 고안되었다. 그러나, PDAF의 경우에는 표적에서 기인한 측정치의 정보 외에 클러터의 정보 또한 자료결합에 활용하므로, 일반적으로 표적추적의 강인성은 향상되지만 추적 정확도 성능은 감소하는 경향이 있다. 이를 보완하기 위해 트랙 존재 확률 개념을 도입한 Integrated Probabilistic Data Association Filter(IPDAF)[12,13,14]가 제안되었고, 단일 표적 추적이 아닌 다수 표적 추적을 위한 Joint Probabilistic Data Association Filter(JPDAF)[15,16], Joint Integrated Probabilistic Data Association Filter(JIPDAF)[17], iterated Joint Probabilistic Data Association Filter(iJPDAF)[18]가 제안되었다. JPDAF는 단일 표적 추적을 가정한 PDAF에서 다수 표적 추적으로의 확장이며, JIPDAF는 트랙 존재 확률 개념을 도입한 단일 표적 추적 IPDAF에서 다수 표적 추적으로의 확장한 형태이다. 또한, iJPDAF는 JPDAF의 과도한 연산량 감소를 위해 제안된 기법으로서 반복 횟수가 1회이면 PDAF와 동일하며, 모든 경우의 수를 고려하여 반복 횟수를 정하면, JPDAF와 동일하다. 연산량 감소와 성능 향상 간 상호절충을 통해 반복횟수를 정하여 효율적인 자료결합 방안을 제시하였다. False Track Discrimination(FTD) 개념을 도입한 Integrated Track Splitting (ITS)[19,20]는 자동개시 확정 후, 내부추적을 통해 FTD인 트랙을 판별하며, 표적으로 확정된 트랙에 대해서만 실질적으로 표적으로 판별 및 추적을 수행하는 견실한 자료결합 기법을 제시하였다.
이와 같이 표적추적 자동개시 및 자동추적에 대한 다양한 자료결합 기법이 제안되었고, 이는 운용자의 업무 과중과 관심표적에 대한 인지 및 관리를 용이하게 하여 왔다.
그러나, 표적추적 자동 개시 및 자동 추적 관점에서 1-point 및 2-point initialization 기법을 활용하여 왔으며, 다음 단계로 실시하는 내부추적에서 클러터도 고려한 자료결합 기법을 적용하여 실제 표적이 아닌 노이즈, 즉 클러터에 대한 추적개시도 상당히 이루어지도록 하고 있다. 특히, 해양환경이 복잡한 상황에서는 이러한 단점이 더욱 발생하고 있다.
본 연구에서는 협대역표적 추적 자동 개시 및 자동 추적에서 정보 엔트로피 개념을 도입하여 클러터에 대한 표적 추적개시는 억제하고, 실표적에 대한 표적 추적개시는 유지하는 기법을 제안한다. 제안한 기법은 해상실험데이터를 기반으로 실시한 시뮬레이션을 통해 검증하였다. 클러터에 대한 자동추적개시를 억제함으로서, 클러터가 많이 발생하는 해양환경에서 협대역표적 추적자동개시의 견실성 향상에 기여를 할 것으로 기대한다.
II. 협대역표적 추적자동개시
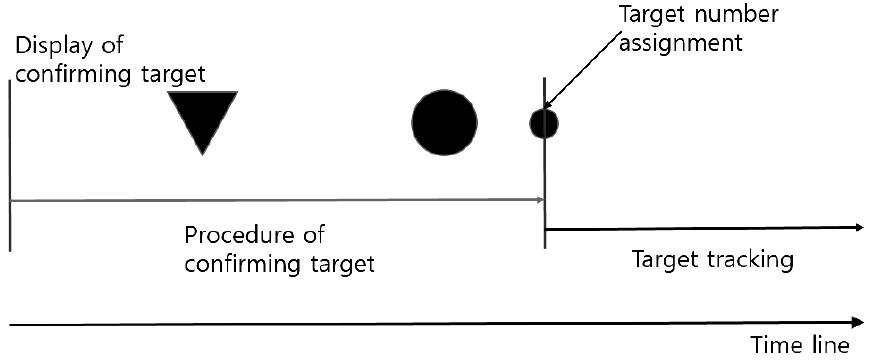
서론에 언급한 바와 같이 표적추적 자동개시 및 자동추적에 대한 다수의 문헌이 있으며, 대표적으로 확률 기반의 방법이 제안된다. 이를 도식도로 나타내면 Fig. 1은 협대역 표적추적의 관리 주기를 표현하고, Fig. 2에서는 협대역 표적추적 자동개시 과정이 총 3단계로 세분화된다.
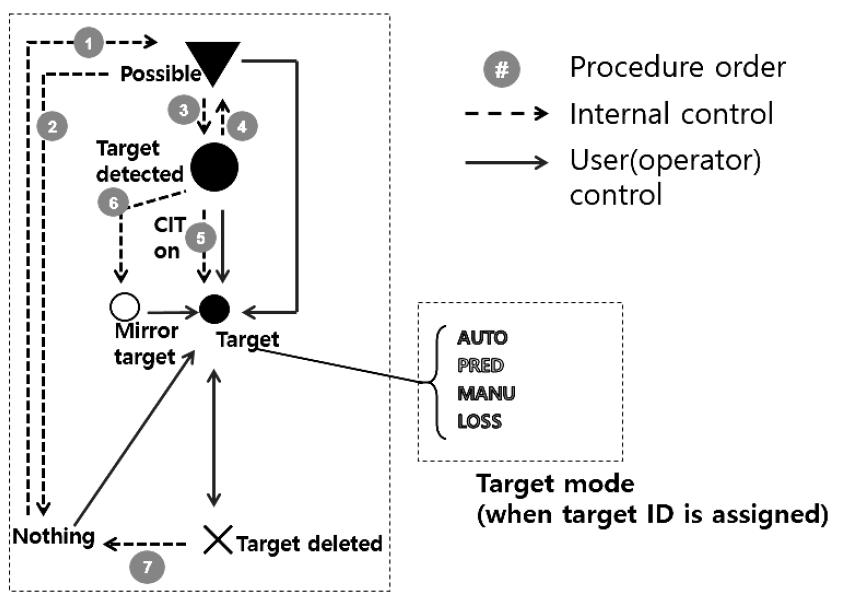
첫 번째 단계는 탐지데이터로부터 추출한 측정치 간에 동일 표적으로서의 연계가능여부를 판단하는 단계이다. 탐지데이터로부터 신호준위에 대한 별도의 문턱값 없이 모든 측정치를 추출하며 이는 낮은 신호준위의 관심표적에 대해서도 표적추적 자동개시가 가능하도록 하기 위함이다. 확률 기반의 기법을 이용하여 탐지데이터 공간 내 모든 측정치를 효과적으로 활용하기 위해서 전체 탐지데이터 공간을 일정한 크기의 그리드로 나눈다. 그리드 별 측정치 최대개수 N을 할당하고 신호준위가 큰 순서로 정렬한다. 이는 추출한 모든 측정치가 표적에서 발생한 것은 아니며, 협대역추적에서 자동개시하는 표적 최대개수는 사전설정값에 국한되어 있으므로 모든 측정치에 대해 표적 자동개시를 할 필요가 없다. 신호준위가 큰 순서로 정렬하므로서 확률적으로 표적일 가능성이 높은 측정치를 효율적으로 우선 표적으로 자동개시한다.
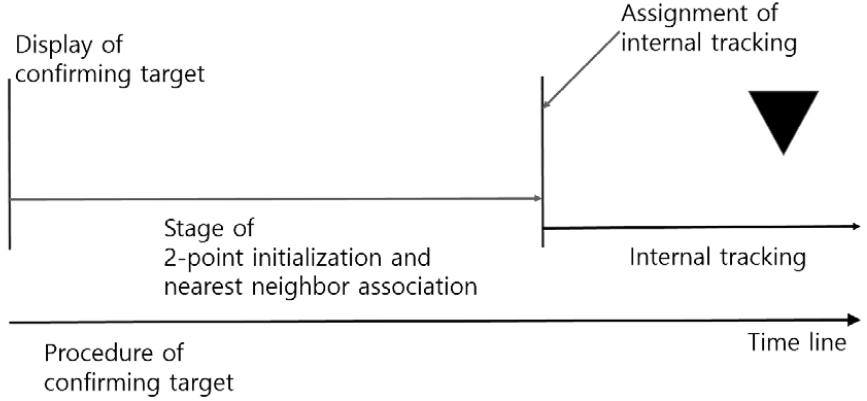
표적 자동개시를 위해서 Fig. 3과 같이 2-point initialization과 NNA를 적용한다. 본 논문에서 제안된 알고리즘 및 성능비교를 위한 대조군으로서의 기존 알고리즘에 동일하게 2-point initialization과 NNA를 적용한다.
2-point initialization은 다음 수식과 같다.
여기에서 에서 는 추정한 상태 변수, 는 샘플링 시간 인덱스, 는 측정치 변수를 나타낸다. 또한, 는 샘플링 시간 인덱스 간의 시간 차, 는 오차 공분산, 는 측정오차, 는 샘플링 시간 인덱스 별 측정치 간 Euclidean distance 오차를 나타낸다. 이는 표적의 천이 구간이 물리적으로 가능한 범위 내에서 동일 표적임을 판단하기 위한 기본 정보를 획득하기 위함이다.
표적의 물리적 천이 구간 가능 범위를 기반으로 Initialization에서 측정치 연계관련유무를 판단하기 위해서 NNA를 활용하며, 트랙 연계에 대한 성능지수[2]는 다음과 같다.
여기에서 의 은 트랙연계 성능지수를 나타내는 Likelihood, 는 샘플링 시간 인덱스, 는 트랙 연계 성능지수에 대한 확률적 표현이다. 는 표적 미존재 가설, 은 표적 존재 가설, 은 표적 트랙 연계 성능지수, 은 클러터 트랙 연계 성능지수를 나타낸다. 또한, 와 는 타원형 연계 측정치 게이트에 대한 방위축과 주파수축 반경 길이, 는 표적, 는 클러터, 는 평균값 0과 분산 의 Gaussian 분포, 은 탐지됨을 의미한다. 는 탐지확률, 는 오탐지확률, 는 단위 시간 별 트랙 연계 성능지수값을 나타내고, 탐지확률과 오탐지확률은 사전에 설정 가능한 값이다. 연계 게이트는 연계 과정에서의 표적 천이 가능 범위를 의미하며, 트랙의 성능지수는 연계하고 있는 트랙에 대한 표적 가능성을 확률로서 나타낸다.
두 번째 단계에서는 표적추적 자동개시를 견실하게 실행하기 위해서 표적번호가 할당되지 않는 상태에서의 내부적인 추적을 시작한다. 이러한 내부 추적에는 이산 선형 칼만필터를 적용하고, 자료결합으로서 SNF와 PNNF를 적용한다.
필터 초기안정화 이전에는 자료결합으로서 SNF를 적용하고, 필터 안정화 이후에는 PNNF를 적용한다. 필터 초기안정화 이전에 NNF 계열의 자료결합을 활용할 경우에 클러터를 연계 및 내부추적하는 상황이 발생할 수 있으므로, 연계 게이트 내 신호크기가 큰 측정치를 기준으로 연계하는 SNF를 적용한다. PNNF의 예측과정은 이산 시간 칼만 필터의 예측과정과 동일하며, 갱신과정에서 연계 게이트 내에 측정치가 없는 경우는 다음과 같다.
갱신과정에서 연계 게이트 내에 측정치가 있는 경우는 다음과 같다.
여기에서 의 는 추정한 상태 변수, 는 예측한 상태 변수, 는 측정치가 연계 게이트 내에 존재할 확률을 나타낸다. 또한, 는 2차원 연계 게이트의 최대 크기, 는 인자에 따른 연계 게이트 부피, 는 오차 공분산을 표현한다. 는 이산 선형 칼만 필터의 이득, 는 이산 선형 칼만 필터의 혁신 공분산, 는 이산 선형 칼만 필터의 예측값과 예측값으로부터 가장 근접해 있는 측정치 간의 Euclidean distance residual이다. 는 측정 행렬, 는 측정오차, 는 클러터 밀도를 나타낸다. PNNF는 필터의 예측값과 예측값으로부터 가장 근접해 있는 측정치를 확률에 기반하여 회귀적으로 연계하며, 연계 게이트 범위를 측정치 연계여부 및 클러터 밀도에 따라 가변적으로 적용한다.
SNF의 트랙 연계 성능지수는 다음과 같다.
여기에서 는 이산 선형 칼만 필터의 예측값과 예측값 기준 연계 게이트 내에서의 신호준위가 가장 큰 측정치 간의 Euclidean distance residual이고, 은 연계 측정치 게이트의 반경이다.
PNNF의 트랙 연계 성능지수는 Eq (27,28,29,30,31,32,33,34)와 동일하다. 트랙 연계 성능지수는 NNA의 트랙 연계 성능지수에서 언급한 바와 같이 표적 가능성에 대한 확률적 표현이며, 자료연계 기법에 따라 확률적 표현이 달라진다.
세 번째 단계에서는 내부 추적 중인 추적표적의 성능지수를 필터 갱신 시 마다 확률적으로 계산하고, 성능지수가 사전 설정한 일정 문턱값 이상이 되면, 추적 중인 표적을 자동개시하고, 표적번호를 할당한다. 표적이 자동개시되면 이산 선형 칼만 필터를 적용하여 추적을 실시한다.
III. 스펙트럼 엔트로피를 활용한 협대역표적 추적 자동개시
본 논문에서는 협대역탐지의 빔-주파수 영역 내 주파수선이 존재하는 영역에서는 노이즈 또는 클러터만 존재하는 영역에 대비하여 신호준위에 대한 정보 엔트로피가 낮아지는 점을 활용하여 견실하게 협대역표적 추적이 자동개시되는 기법을 제안한다.
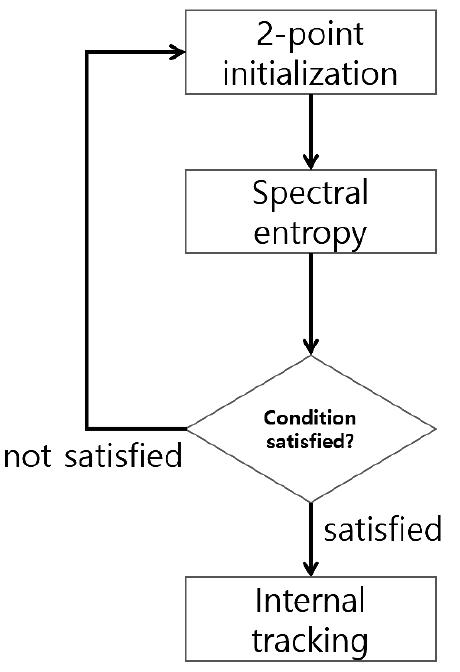
클러터에 대한 자동표적개시를 감소시키기 위해 2-point initialization을 적용하는 단계에서 기존의 연계 기법 외에 추가적으로 측정치에 대한 정보 엔트로피 기법을 적용한다. 기존의 NNA 연계 기법을 적용하면서 추출한 해당 측정치에 대한 정보 엔트로피를 계산한다. 연계확률과 정보 엔트로피에 대해서 사전에 설정한 임계값 조건을 만족하면 표적추적 자동개시를 위한 두 번째 단계로 진입한다. 이에 대한 처리절차와 순서도는 Figs. 4, 5와 같다.
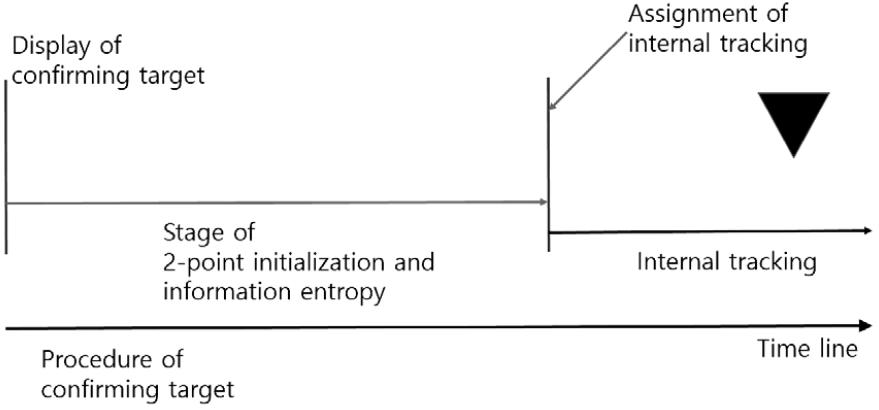
신호준위에 대한 정보 엔트로피는 빔별 스펙트럼에서 추출한 측정치에 대해 사전설정한 빔 및 그리드 별로 산출하며 다음과 같다.
여기에서 는 빔 및 그리드별 측정치의 신호준위, 은 빔별 그리드 총 개수를 나타낸다.
표적추적 자동개시를 위한 조건은 연계관련 확률과 스펙트럼 정보 엔트로피로 구성되며, 임계값 조건을 만족시키는 경우에는 자동개시를 위한 두 번째 단계로 진입한다. 임계값 조건의 만족여부는 사전 설정값 이상의 연계관련 확률 및 사전 설정값 이하의 정보 엔트로피일 때 조건을 만족하고, 이 외의 경우에는 조건을 만족하지 않음을 의미한다. 자동개시를 위한 두 번째 단계 이후의 과정은 기존의 알고리즘과 동일하다.
스펙트럼 정보 엔트로피 성능지수는 다음과 같다.
여기에서 는 스펙트럼 정보 엔트로피 변수, 는 샘플링 시간 인덱스, 는 샘플링 시간 인덱스 간 스펙트럼 정보 엔트로피 차이값을 나타낸다. 의 은 스펙트럼 정보 엔트로피 성능지수를 나타내는 Likelihood, 는 스펙트럼 정보 엔트로피 성능지수에 대한 확률적 표현이다. 는 표적 스펙트럼 정보 엔트로피 미존재 가설, 은 표적 스펙트럼 정보 엔트로피 존재 가설, 은 표적 스펙트럼 정보 엔트로피 성능지수, 은 클러터 스펙트럼 정보 엔트로피 성능지수를 나타낸다. 또한, 는 그리드의 방위축 샘플링 크기, 은 조건만족을 의미한다. 는 표적 스펙트럼 정보 엔트로피 탐지 확률, 는 표적 스펙트럼 정보 엔트로피 오탐지확률, 는 단위 시간 별 스펙트럼 정보 엔트로피 성능지수값을 나타낸다. 정보 엔트로피 성능지수는 기존 연계확률 기반의 성능지수와 동일하게 트랙의 표적 가능성을 확률적으로 표현한다.
IV. 해상실험데이터 시뮬레이션 결과 및 고찰
본 논문에서 제안한 방법을 검증하기 위하여 해상실험데이터를 활용하였다. 해상실험데이터는 포항 동방에서 해상의 모의음원에서 방사한 신호를 수중운동체가 수신한 데이터이다. 탐지데이터는 수중운동체의 LOFAR 신호처리를 한 결과를 활용하였으며, 모의음원에서 방사한 신호는 광대역신호와 총 5개의 토널로 구성되었고, 수중운동체를 중심으로 원기동을 하였다. Fig. 6은 관심표적의 주파수선을 포함하지 않는 그리드에 대한 신호준위 분포를 나타내며 Fig. 7은 관심표적의 주파수선을 포함하는 그리드에 대한 신호준위 분포를 나타낸다.
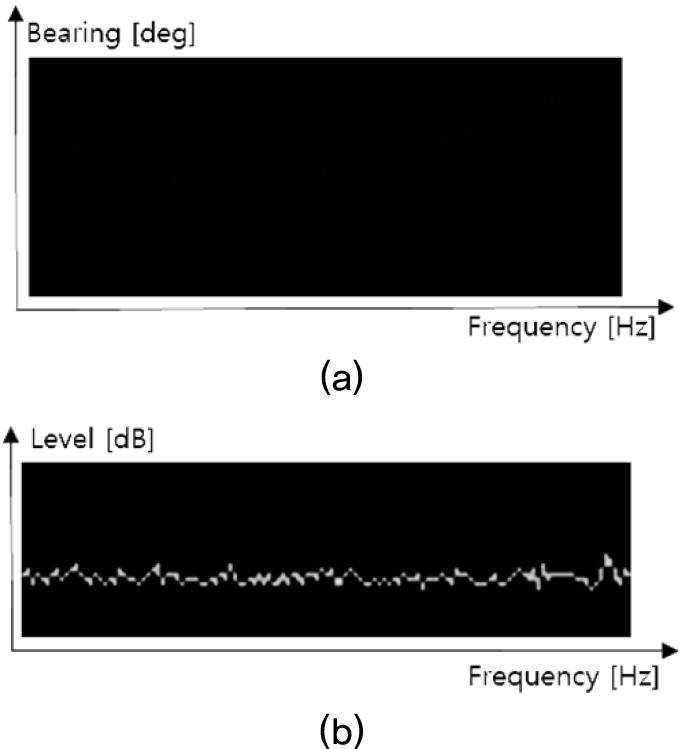
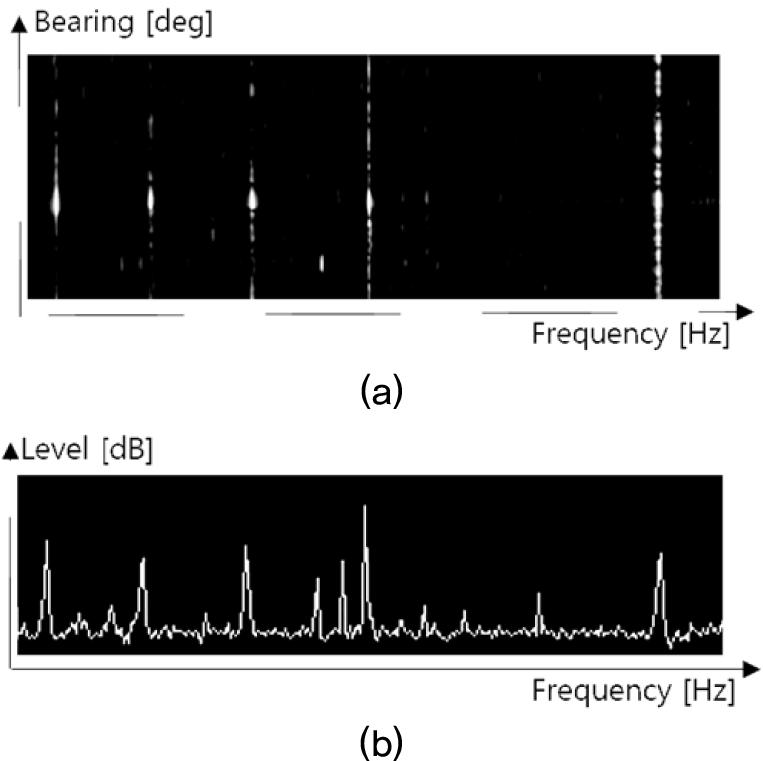
Fig. 8은 관심표적에 대한 정보 엔트로피의 분포를 나타내며 Fig. 9는 클러터에 대한 정보 엔트로피의 분포를 나타낸다. 관심표적에 대한 정보 엔트로피와 클러터에 대한 정보 엔트로피가 분리되어 식별됨을 알 수 있다.
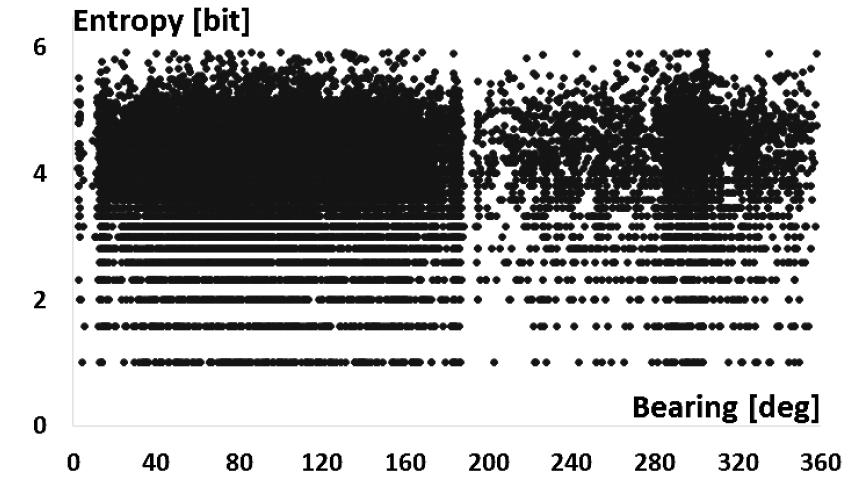
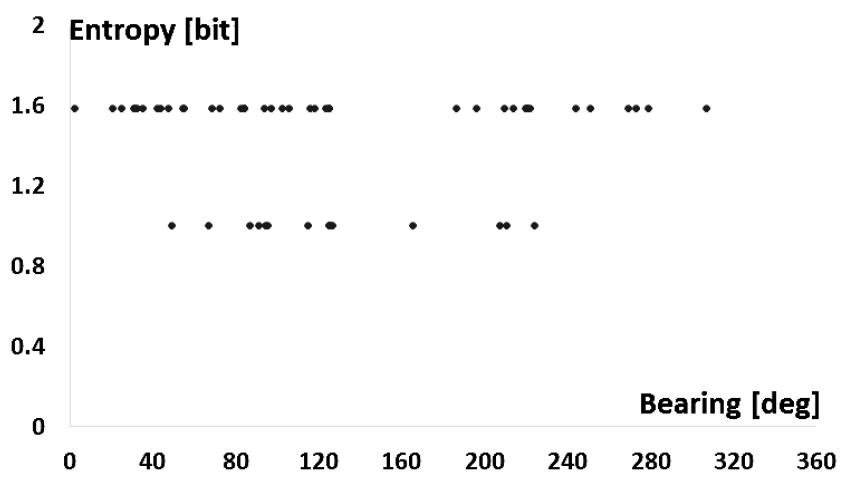
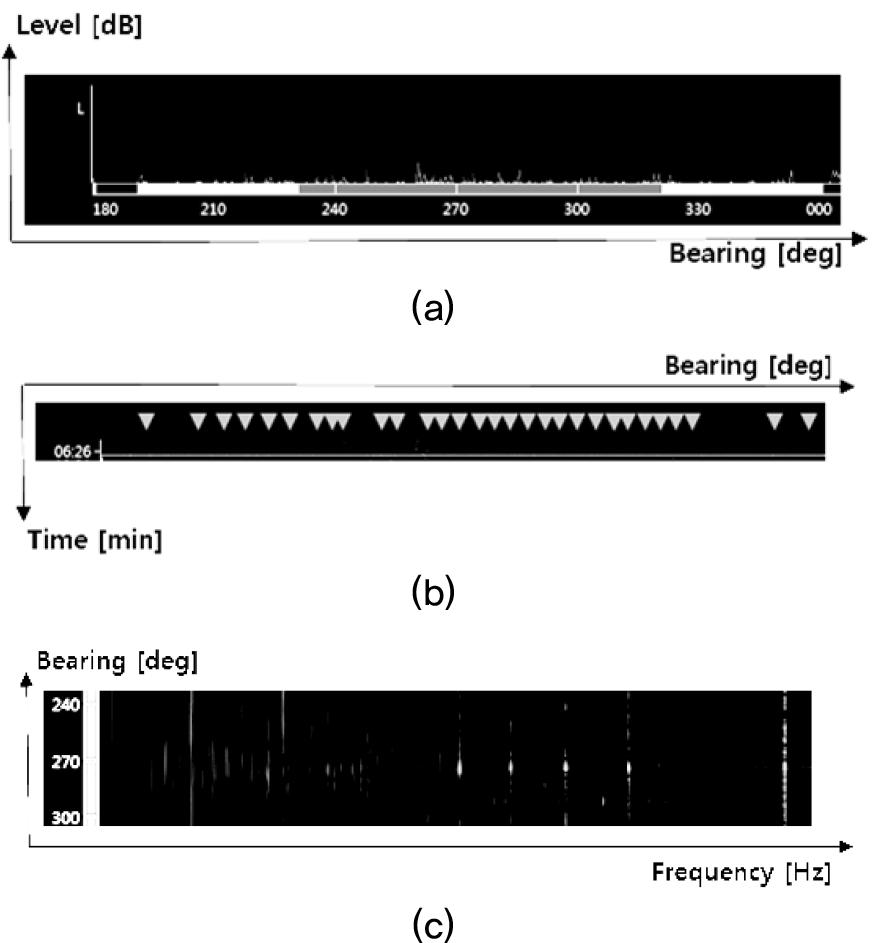
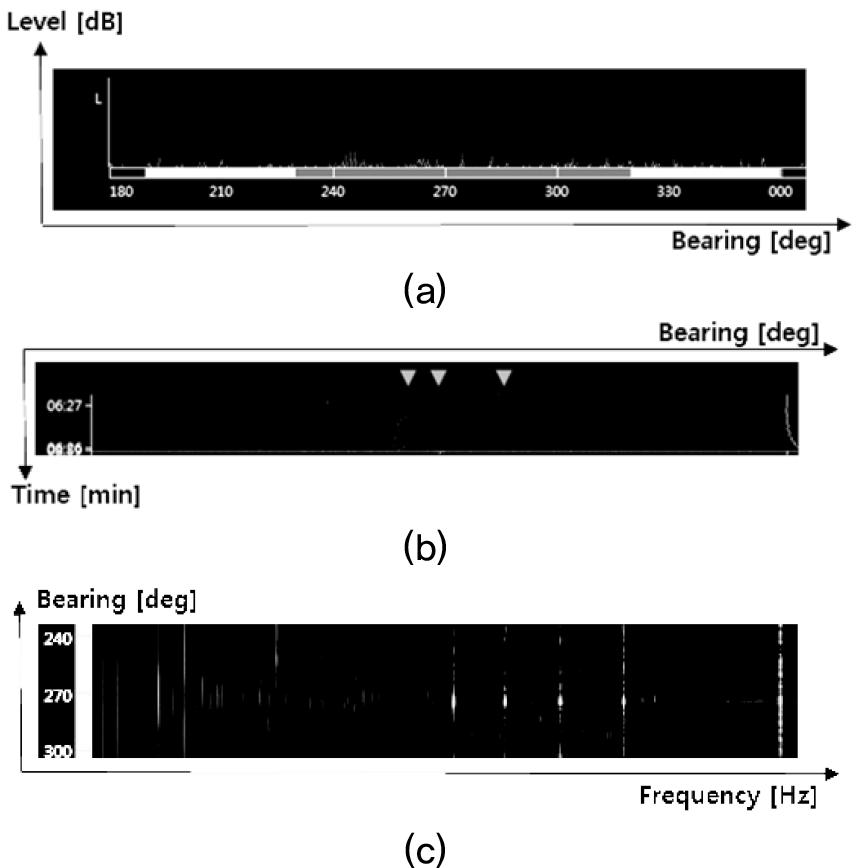
Fig. 10은 기존 알고리즘을 적용한 결과이며 Fig. 11은 본 논문에서 제안한 알고리즘을 적용한 결과이다. 제안한 알고리즘이 기존 알고리즘에 대비하여 관심표적에 대한 표적추적 자동개시는 유지하면서 클러터에 대한 표적추적 자동개시는 억제하는 효과가 있음이 Fig. 10(b)와 Fig. 11(b)에서 확인된다.
정보 엔트로피에 대해 통계적인 검증을 보완하기 위하여 추가적인 해상실험데이터를 활용하고, 표적과 클러터에 대한 정보 엔트로피를 분석하였다. 관심표적과 클러터에 대한 정보 엔트로피의 분포가 Figs. 12, 13의 분포를 나타내었으며, 관심표적과 클러터에 대한 정보 엔트로피 분포가 분리되어 식별됨을 알 수 있다.
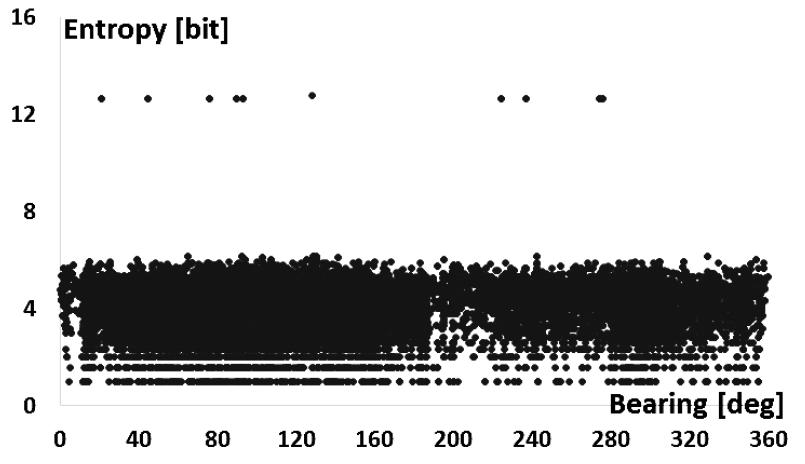
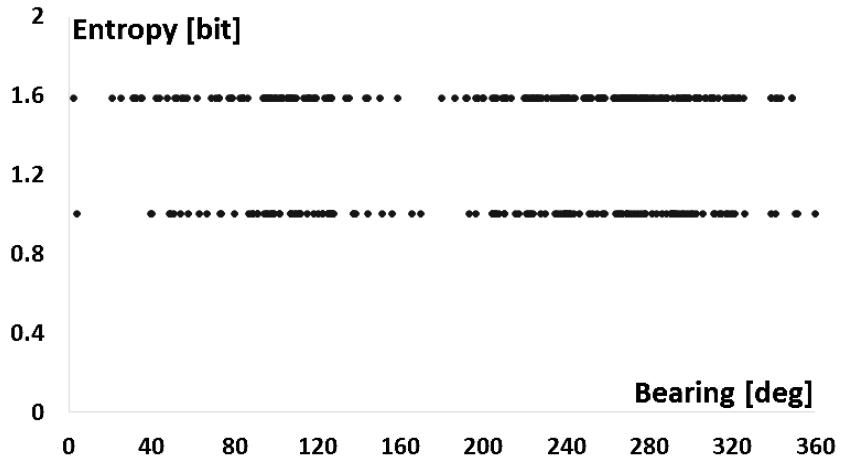
Table 2는 해상실험데이터를 20회 반복 적용하여 산출한 결과이며, 제안한 알고리즘을 적용하였을 경우와 기존 알고리즘을 적용한 경우에서 관심표적을 표적추적 자동개시한 결과 및 클러터를 표적추적 자동개시한 결과를 보여준다.
V. 결 론
본 논문에서는 견실한 협대역표적 자동개시를 위한 알고리즘을 제안한다. 제안한 알고리즘은 탐지데이터에서 추출한 측정치에 대해 연계관련확률과 정보 엔트로피를 결합 및 적용한다. 이는 주파수선이 존재하는 빔-주파수 영역은 노이즈만 존재하는 빔-주파수 영역에 대비하여 정보 엔트로피가 낮아진다는 점을 활용하고, 다양한 해상실험데이터를 통해 제안한 기법이 기존 기법에 대비하여 관심표적에 대한 표적추적 자동개시는 유지하면서 클러터에 대한 표적추적 자동개시는 억제하는 효과가 있음이 확인되었다. 향후 다양한 토널 성분으로 구성된 표적에 대한 해상실험데이터 분석과 측정치 추출 및 선별을 위한 그리드 크기를 자동으로 최적화하는 방안이 필요할 것으로 판단된다.
