

I. 서 론
II. 음향 인텐시티 측정법
III. 문제 정의
IV. 딥러닝 기반 음향 인텐시티 벡터 보상
V. 결과 및 토의
5.1 실험 설정
5.2 음향 인텐시티 벡터 보상 결과
VI. 결 론
I. 서 론
음원 위치 추정 기술은 국방 시스템, 로봇, 스마트 인프라 등 다양한 산업에서 활용되어온 기술로써, 최근 가상 현실 또는 스마트 홈 기술 등을 통해 그 중요성이 더욱 강조되고 있다.[1,2]
음원의 도달 방향(Direction of Arrival, DoA) 추정 방법 중 대표적으로는 마이크로폰 어레이를 통해 도달시간 차를 이용하는 방법 및 빔포밍이 널리 사용된다.[3,4] 이러한 방법에서 마이크로폰에 도달하는 위상차를 정밀하게 구분하기 위해서 측정하고자 하는 소리의 파장에 비례하여 마이크로폰 어레이의 크기가 결정되므로, 따라서 낮은 주파수를 포함하여 광범위한 주파수 특성을 갖는 음원에 대한 위치 추정을 수행하기 위해서 시스템 구현에 큰 공간이 필요하다.
음향 인텐시티 측정법은, 마이크로폰에서 측정되는 음압의 유한차분에 따라 계산되는 입자속도를 기반으로 능동음향인텐시티 벡터를 추정하여 음원의 위치를 계산하는 방식이다. 유한차분에 따른 오차를 줄이기 위해 마이크로폰 간격이 작은 형태의 모듈이 사용되므로, 비교적 좁은 공간에도 구현이 가능한 장점이 있다.[5,6] 그러나, 마이크로폰 간격에 비해 짧은 파장을 가지는 소리에 대해서는, 측정 원리에 따라 인텐시티 계산 오차가 커지게 되므로 음원 위치 추정을 수행할 수 있는 주파수 대역이 제한된다. 따라서 이러한 문제를 해결하기 위해 신호처리 및 마이크로폰 어레이 설계 방법이 제안되었다.[7,8] 또한 딥러닝 기술은 데이터에 내재된 규칙을 학습하는 이점이 있으며, 따라서 음원 위치 추정 분야에서도 이러한 기술이 많이 적용되고 있다.[9,10]
본 연구에서는 마이크로폰 어레이를 통해 음향 인텐시티를 계산하는 데 있어, 딥러닝을 적용하여 모든 주파수 대역에서 높은 정확도로 음원의 위치를 추정하는 방법을 제안한다. 정사면체 형태의 마이크로폰 어레이가 적용되었으며, 다양한 크기를 갖는 어레이에 대해 적용하기 위해서 헬름홀츠 수에 대한 추정 성능을 비교한다. 결과적으로 본 연구에서 제안하는 딥러닝 모델은 측정을 통해 계산된 인텐시티 벡터를 헬름홀츠 수에 대하여 보상하는 것을 목적으로 한다.
II. 음향 인텐시티 측정법
마이크로폰 어레이로부터 계산되는 능동 음향 인텐시티 벡터는, 음향 중심을 기준으로 데카르트 좌표의 x, y, z축 방향의 벡터 성분으로 계산되며,[11] 이를 기반으로 음향 중심에 도달하는 음원 방향에 대한 추정이 가능하다. 실제 음원 전파에 따른 음향인텐시티 벡터와 측정을 통해 계산되는 인텐시티 벡터 사이의 관계를 다음의 식으로 표현할 수 있다.
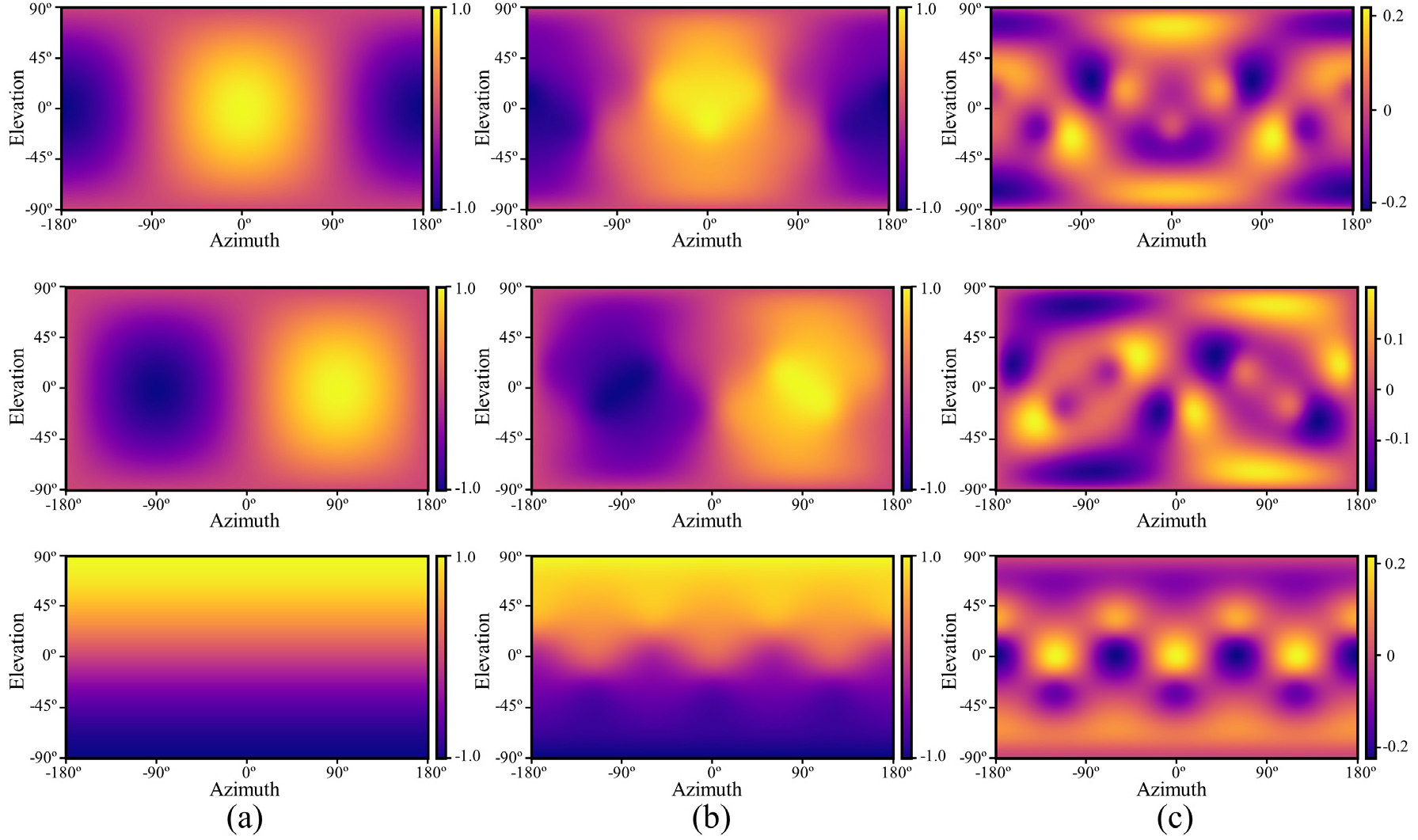
여기서 는 p-p 방법으로 측정된 인텐시티 벡터이고, 는 마이크로폰 어레이의 음향 중심에 도달하는 음원 도달 방향에 대한 방향벡터를 나타내며, kd는 헬름홀츠 수를 나타내고, 여기서 k는 파수, d는 마이크로폰 간격이다. 는 특히 높은 kd 에서 불규칙한 어레이 방향 응답으로 인해 음향인텐시티 벡터를 통한 음원 위치 추정 결과에서 공간 편향을 초래한다.[8] 이러한 위치추정 오차는 p-p 방법에 따라 입자속도를 계산하는 과정에서 발생하는 유한차분오차에 기인하며, 따라서 kd 가 원주율에 가까워질수록 추정 오차가 커진다.
Fig. 1은 kd = 3.0에서 각 인텐시티 벡터 성분 Ix, Iy, Iz에 대한 측정 오차를 나타낸다.
III. 문제 정의
본 연구의 목표는 음향 인텐시티 측정에 따른 인텐시티의 편향을 보상하여 정확한 음향 인텐시티를 추정하는 것이다. 이를 위해 를 통해 측정된 인텐시티 벡터 를 보상하기 위해 아래와 같이 오차를 보상하는 모델을 수식으로 표현하면 다음과 같다.
여기서 는 딥러닝 모델 을 적용하여 계산된 보상된 인텐시티 벡터를 나타낸다. 한편, 제안하는 딥러닝 모델은 헬름홀츠 수에 대한 함수로써, 다양한 크기의 정사면체 어레이에 본 모델을 적용할 수 있도록 하였다.
IV. 딥러닝 기반 음향 인텐시티 벡터 보상
본 연구에서는 음향 인텐시티 벡터에서 나타나는 오차를 보상하기 위해 밀집 층 기반의 딥러닝 모델의 적용을 제안한다.
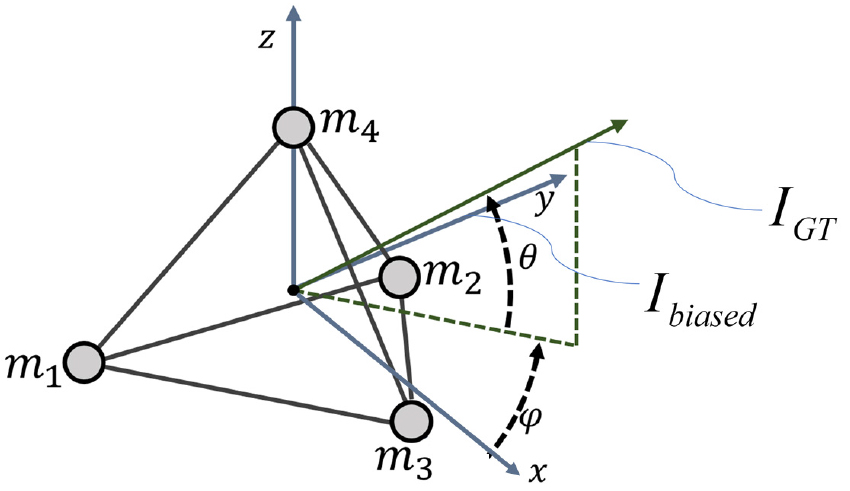
Fig. 2는 3차원의 및 1차원의 kd를 입력받아, 모델 내에서 32차원 및 64차원의 고차원으로 확장하여 특징을 학습하고, 최종적으로 3차원의 를 출력하는 딥러닝 모델을 나타낸다.

Fig. 2.
(Color available online) Proposed deep learning-based model for sound intensity vector compensation. The input is biased intensity components and Helmholtz number, and the output is compensated intensity components. Both intensities are unit vector form which represents DoA information of sound source. Here, the numbers in parentheses represent the dimensions of the dataset.
여기서, 선형계층 및 안정적 학습을 위한 배치정규화 및 시그모이드 활성화 함수가 적용되었다. 제안된 모델은 특징을 고차원으로 확장하고 다시 축소하는 과정을 통해, 음향 인텐시티 보상을 위한 복잡한 패턴을 고차원 공간에서 효과적으로 학습하며, 이를 통해 정확한 보상을 수행할 수 있도록 한다.
모델 학습을 위한 손실 함수는, 평균절대오차()와 단위 벡터 손실 함수()로 구성된 복합 손실 함수를 사용하며 다음과 같다.
여기서 는 와 간의 오차를 최소화하는 것을 목표로 하며, 는 예측된 의 크기를 1로 제한하여 단위 벡터가 되도록 학습을 조력한다.
두 손실 함수 간의 가중 계수는 𝜆 = 0.1 및 학습률은 0.001로 설정되었으며, 모델 최적화는 Adam Optimizer를 사용하여 수행되었다.[12] 하이퍼 파라미터는 학습과정에서의 검증을 통해 선정되었는데, 여기서 가중 계수 𝜆는 단위 벡터 손실함수가 평균 절대오차의 수렴을 조력할 수 있는 값으로 선정되었으며, 학습률은 전체 손실값을 효율적으로 감소시키는 값으로 선정되었다.
V. 결과 및 토의
5.1 실험 설정
딥러닝 기반의 인텐시티 벡터 계산 방법에 대한 유효성을 검증하기 위해서 시뮬레이션을 수행하였으며, 이를 위해 d = 0.14 m 인 정사면체 마이크로폰 어레이를 선정하였고 Fig. 3에 나타내었다. 테스트에 적용할 음원으로는, 방위각 𝜙 = [-180°, 180°], 고도각 𝜃 = [-90°, 90°] 범위에서 전파되는 평면파를 고려하였으며, 헬름홀츠 수 범위 kd = [0.1, 3.0]에 해당하는 주파수 범위 f = [40 Hz, 1170 Hz]의 대역 제한 백색 잡음 신호를 갖는 음원에 대한 위치추정 과정을 모사하였다.[7] 제안 모델의 학습을 위해, 전체 방위각 범위 [-180°, 180°], 고도각 범위 [-90°, 90°], 그리고 kd 범위 [0.1, 3.0] 에 대하여 300,000개의 데이터 셋을 학습데이터로 사용하였다.
와 사이의 평균제곱오차(Mean Squared Error, MSE) 및 DoA 오차를 통해 제안된 모델의 성능을 평가하였다. 여기서 음원 도달 방향 오차는 인텐시티 벡터 사이의 각도 거리에 해당하며 다음과 같이 계산된다.
5.2 음향 인텐시티 벡터 보상 결과
Fig. 4와 Table 1은 제안된 모델을 통한 음원 추정 테스트 결과에 대한 MSE와 DoA 오차를 나타낸다. 본 결과는 64,800개의 음원 방향에 대한 평균값을 나타낸다. 실험결과를 통해 전체 헬름홀츠 수 범위 내에서 MSE 및 DoA 오차가 크게 감소되는 것을 관찰할 수 있다. 딥러닝이 적용되지 않은 결과에서는 높은 kd에서 위치 추정 오차가 크게 발생하지만, 딥러닝 적용 결과에서는 추정 오차가 크게 저감되는 것을 볼 수 있고, 특히 kd < 2.7 범위에서는 평균 DoA 오차가 0.5°보다 낮은 것을 확인할 수 있다. 그러나 kd = 1 인 경우, 딥러닝 모델을 통해 계산된 결과의 MSE가 더 크게 나타나는 것을 볼 수 있는데, 이는 제안 모델이 높은 kd에서 발생하는 큰 오차를 보상하는 방향으로 학습 됨에 따른 것으로 볼 수 있다. 향후 연구에서는 이러한 오차의 원인을 분석하고, 세부보정을 통해 학습 모델을 개선할 수 있을 것으로 생각된다.

Table 1.
Quantitative analysis of the test result for kd is 1, 2 and 3.
| Evaluation metric | kd = 1 | kd = 2 | kd = 3 | |
| MSE | Biased | 2.22E-05 | 5.40E-04 | 7.52E-03 |
| Compen. | 1.02E-04 | 1.02E-04 | 4.19E-03 | |
|
DoA error (°) | Biased | 0.43 | 2.16 | 8.05 |
| Compen. | 0.23 | 0.22 | 1.14 | |
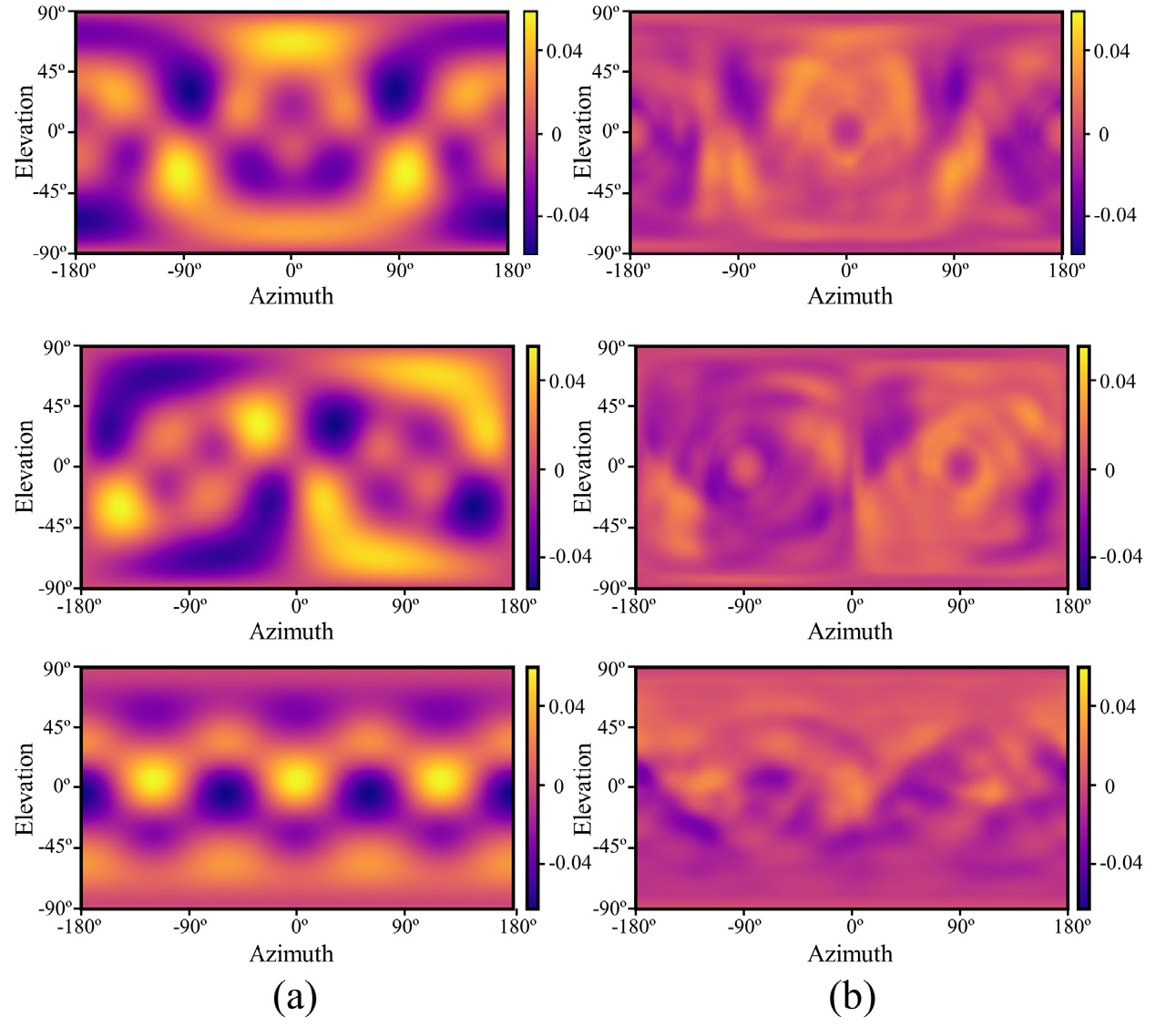
Fig. 5는 kd = 2에서 와 의 인텐시티 벡터 구성 요소의 추정 오차에 대한 결과를 나타낸다. 선행연구에 따르면 음원 위치 추정 오차는 인텐시티 벡터의 방향 구배에 비례하므로,[8] Fig. 5(b)와 같이 딥러닝 모델을 통한 계산 결과에서 인텐시티 오차의 크기가 줄어든 것이 결국 위치 추정 오차가 줄어들게 된 직접적인 원인임을 확인할 수 있다.
VI. 결 론
본 연구에서는 마이크로폰 어레이를 이용하여 음향 인텐시티 벡터를 추정하는 방법에 딥러닝을 적용하여, 높은 헬름홀츠 수에서 나타나는 편향 오차를 저감함으로써 정확한 음원 위치 추정을 수행하였다. 이를 통해, 주로 낮은 헬름홀츠 수 대역에 해당하는 환경에만 적용되었던 한계를 극복하고, 더 높은 주파수 대역까지 측정 범위를 확장 시킬 수 있다.
정사면체 어레이는 4개의 마이크로폰을 사용하여 3차원에 대한 측정이 가능하므로 공간 효율성이 높다. 한편, 본 연구에서 제시하는 딥러닝 모델은 헬름홀츠 수에 대해 적용되며, 따라서 다양한 크기를 갖는 정사면체 어레이를 활용하는데 있어서 범용성을 추구하고, 특히 kd < 3에서 높은 정확도로 음원의 위치를 추정할 수 있음을 시뮬레이션을 통해 검증하였다. 따라서, 본 기술은 가상 현실, 스마트 홈 기술, 로봇공학, 그리고 국방 시스템과 같이 복잡한 음향 환경에서의 음원 추적 및 고해상도 음향 이미징 분야 등 유용하게 적용될 수 있다. 향후 연구에서는 본 딥러닝 기반 추정 방법을 실제 실험 결과에 적용하고 검증을 수행함으로써, 장점에 비해 다소 제약이 많은 인텐시티 추정 기반의 음원 위치 추정법의 활용성을 높일 수 있을 것으로 기대한다.
