

I. 서 론
화자 인증(Speaker Verification, SV) 시스템은 주어진 입력 발성이 대상 화자가 발화한 것인지를 판단한다. 이를 위해 SV 시스템은 입력 발성으로부터 화자 특징을 추출하는 화자 특징 추출기를 포함한다. SV는 사전에 등록된 대상 화자의 화자 특징과 입력된 발성으로부터 추출한 화자 특징의 유사도를 계산하여 사전에 정의한 임계값을 기준으로 일치 여부를 판단한다. 이 때, 화자 특징 사이의 유사도를 측정하는 방법으로는 코사인 유사도를 널리 사용한다.
최근 다양한 분야에서 심층 신경망(Deep Neural Network, DNN)의 우수성을 입증하고 있으며, 화자 인증 시스템 또한 DNN을 사용하여 연구되고 있다. 이에 따라, 대다수의 화자 특징 추출기는 주어진 발성으로부터 Mel-frequency Cepstral Coefficients(MFCC) 등의 음향 특징을 추출한 뒤, 이를 DNN에 입력하여 화자 특징을 추출한다.[1] 하지만, 최근 원시파형을 직접 DNN에 입력하는 기법들이 제안되었다.[2,3,4,5] 원시파형을 DNN에 직접 입력할 경우, DNN의 합성곱 은닉층이 다양한 주파수 대역의 가중 합을 계산함으로써 기존의 음향 특징에 포함된 주파수 변환을 대체할 수 있다고 보고된다.
본 연구의 이전 연구에서는 Reference [5]에서 제안된 원 음성 화자 특징 추출기(RawNet)를 개선하는 연구를 수행하였다.[5] RawNet은 1차원 합성곱 은닉층을 사용하여 원시 신호로부터 필터와 프레임을 나타내는 2차원 특징 지도를 추출한다. Reference [6]에서는 개선을 위해, RawNet의 특징 지도로부터 도출한 스케일 벡터를 이용하여 분별력을 강화하는 특징 지도 스케일링(Feature Map Scaling, FMS) 기법을 제안하고, 이를 적용한 화자 특징 추출기인 RawNet2를 제안하였다. 하지만, FMS는 동일 스케일 벡터를 특징 지도와의 덧셈에도 사용하고, 곱셈에도 사용하기 때문에 스케일 벡터가 두 연산에 동시에 최적화되기 어렵다는 한계를 지닌다. 또한, Reference [6]에서는 시그모이드 비선형 활성 함수를 이용하여 스케일 벡터를 계산하기 때문에, 곱셈에 사용할 경우에는 문제가 발생하지 않지만, 덧셈에 사용할 경우 최댓값이 1로 제한된다는 한계가 존재한다. 본 연구에서는 이러한 한계점을 극복하기 위해, 별도로 학습하는 파라미터인 α를 특징 지도에 더한 뒤, 스케일 벡터를 곱하는 기법을 제안한다. 이는 특징 지도에 0에서 1 사이의 한정된 값을 더하는 대신 임의의 학습 가능한 실수 값 α를 더하는 것이 특징 지도의 분별력 향상에 더욱 효과적일 것이라는 가정에 기반한다. 구체적으로, 스칼라 α를 사용하여 특징 지도의 모든 필터에 동일한 값을 적용하는 방식과, 벡터 α를 사용하여 특징 지도의 각 필터에 상이한 값을 더하는 기법을 탐구한다.
본 논문의 II장에서는 본 논문의 기본이 되는 이전 연구 내용으로 DNN을 이용하여 원 음성으로부터 화자 특징을 추출하는 원시파형 화자 특징 추출기를 소개한다. III장에서는 제안한 특징 지도 α-스케일링 기법을 설명한다. IV장은 제안한 기법들을 이용한 원 음성 화자 인증 특징 추출기를 이용하는 화자 인증 시스템의 실험 설계를 기술하며, 실험 결과를 분석한다. 마지막으로 V장에서는 결론을 기술한다.
II. 원시파형 화자 인증
본 논문의 기초가 되는 원시파형을 직접 DNN에 입력하는 화자 특징 추출기는 Reference [2]에서 처음 제안되었다. References [3], References [4], References [5], References [6]는 새로운 목적 함수를 추가하고, Gated Recurrent Unit(GRU) 은닉층을 사용하고, FMS 기법을 적용함으로써 Reference [2]의 화자 특징 추출기를 확장하였다. 본 논문에서는 Reference [6]에서 제안된 FMS 기법을 적용한 RawNet2 화자 특징 추출기를 소개하고, 이를 본 연구의 베이스라인으로 사용한다. RawNet2는 합성곱 신경망(Convolutional Neural Network, CNN)을 이용하여 프레임 단위 특징을 추출하며, GRU 층을 이용하여 추출한 복수의 프레임 수준 특징들을 단일 발성 단위 특징으로 변환한다. 이 때, CNN에 Batch Normalization(BN) 층, Leaky ReLU 비선형 활성 함수 및 FMS 기법을 이용하여 Reference [7]에서 소개된 잔차 연결을 적용한 블록을 구성한다. 화자 특징은 추출된 발성 단위 특징을 1개의 전결합(Fully Connected, FC) 은닉층에 입력하여 추출한다. DNN의 학습 단계에서 화자 특징 뒤에 출력층을 추가하여 화자 식별기로 학습을 수행하고, 평가 시에는 출력층을 제거하여 그 이전 층의 출력이 화자 특징이 된다. Table 1은 RawNet2의 구조와 RawNet2에서 사용하는 잔차 연결을 적용한 블록을 나타낸다.
Table 1.
DNN architecture of RawNet2.[6] Strided conv refers to a convolution layer which has a stride size identical to the length of filters. The residual block proposed in this paper can be obtained by replacing FMS to α-FMS.
FMS 기법은 화자 특징 추출기 내 각 특징 지도의 분별력을 향상시키기 위해 제안되었다. 특징 지도의 각 필터에 각각 존재하는 정보를 서로 섞어주는 Hu et al.[8]의 연구와 고차원 특징 공간에서의 작은 값의 변화가 분별력에 큰 영향을 미친다는 Zhang et al.[9]의 연구에 착안하여, FMS 기법은 스케일 벡터를 이용해 각 필터에 0에서 1 사이의 값을 더하거나 곱하거나, 혹은 두 방식을 순차적으로 적용하여 특징 지도를 강화한다.
Fig. 1은 FMS 기법을 나타내며, 구체적인 동작은 다음과 같다. 먼저 FMS 기법을 적용하기 전 특징 지도 에 전체 평균 풀링층과 1개의 FC 은닉층을 이용하여 스케일 벡터 를 생성한다. 여기서 와 는 각각 특징 지도의 필터 개수와 시간 축 프레임의 개수를 나타낸다. 이후 FMS 기법이 적용된 특징 지도 은 아래 Eqs. (1) ~ (4)를 이용하여 계산한다.
| $$M’=M\oplus S.$$ | (1) |
| $$M’=M\otimes S.$$ | (2) |
| $$M’=(M\oplus S)\otimes S.$$ | (3) |
| $$M’=(M\otimes S)\oplus S.$$ | (4) |
Eqs. (1) ~ (4)에서 와 는 각각 원소별 덧셈과 곱셈을 의미하며, 는 시간축 T의 길이만큼 확장하여 사용한다. 본 연구에서는 추출된 화자 특징을 이용하여 화자 인증을 수행할 때, 별도의 분류기를 사용하는 대신 두 벡터간의 유사도를 측정하는 방법으로 코사인 유사도 기법을 활용한다.

Fig. 1.
(Color available online) Illustration of the FMS method (Illustration is modified from that of Reference [6]).
III. α-특징 지도 스케일링
Reference [6]에서는 실험을 통해 Eqs. (1) ~ (4)가 모두 베이스라인 대비 동일 오류율을 효과적으로 감소시킴을 보고하였다. 이 중 Eq. (4)의 성능 향상 정도가 가장 큼을 확인하고, RawNet2에 Eq. (4)를 적용하였다. 하지만, 본 연구에서는 Eq. (4)가 아래 Eq. (5)와 같이 실제로는 특징 지도에 상수 1을 더한 뒤 스케일 벡터를 곱하는 것과 동일하다고 분석한다.
| $$M’=(M\oplus1)\otimes S.$$ | (5) |
Eq. (3)과 Eq. (5)를 비교할 경우, 스케일 벡터를 더하는 것보다 상수 1을 더하는 것이 성능 향상 폭이 더욱 큼을 확인할 수 있다. 0에서 1 사이의 변수를 더하는 것보다 상수 1값을 특징 지도의 각 필터에 더하는 것이 더욱 우수한 성능을 보인다면, 특징 지도에 더하는 값을 0에서 1사이의 변수로 한정하는 기법에 비해 DNN의 다른 파라미터들과 같이 학습이 가능한 실수 파라미터를 이용하여 다양한 값을 더하는 것이 특징 지도의 분별력 향상에 더욱 효과적일 수 있을 것이다.
위 분석을 바탕으로 본 논문에서는 별도의 학습 파라미터 α를 사용하여 아래 Eq. (6)과 같이 특징 지도를 강화하는 α-FMS 기법을 제안한다.
| $$M’=(M\oplus\alpha)\otimes S.$$ | (6) |
구체적으로, 스칼라 α를 사용하는 경우와 벡터 α를 사용하는 기법을 제안한다. 스칼라 α를 사용할 경우, 특징 지도의 모든 필터에 동일한 α를 더하는 것을 의미한다. 이것은 Eq. (5)에서 특징 지도의 모든 필터에 상수 1을 더한 경우에 성능이 향상되었으므로 상수 대신 학습 파라미터를 더하도록 변경한 것에 해당한다. 벡터 α를 사용할 경우, 스케일 벡터와 동일하게 특징 지도의 각 필터에 서로 다른 값을 더하는데, 스케일 벡터가 0에서 1 사이의 실수를 더하는 반면, 본 연구에서는 전체 실수 영역을 사용한다. Fig. 2는 제안한 α-FMS 기법을 나타낸다. 본 연구에서는 α-FMS가 FMS의 한계점을 보완하여 더욱 효과적으로 특징 지도를 강화할 수 있을 것이라고 가정하고, 실험을 통해 이를 검증한다.

IV. 실험 설계 및 결과
4.1 데이터셋
본 연구에서는 VoxCeleb2[10] 데이터셋을 DNN 학습세트로 이용하며, VoxCeleb1[11] 평가세트를 이용하여 동일 오류율을 측정한다. VoxCeleb2는 6,112 화자가 발화한 1,000,000개 이상의 발성으로 구성되어 있다. VoxCeleb1 평가세트는 40 화자의 발성으로 구성되어 있으며 37,720개의 trial에 대한 유사도 점수를 이용하여 동일 오류율을 계산한다. 모든 발성은 16 kHz sampling rate, 16-bit resolution, mono로 녹음을 진행하였다.
4.2 실험 설계
본 논문에서는 https://github.com/Jungjee/RawNet에 공개되어 있는 화자 특징 추출기를 베이스라인으로 사용하며, Eqs. (1) ~ (4)에 나타난 FMS 기법을 적용하여 실험을 진행하였다. DNN의 첫 은닉층의 경우 Sinc-conv[12] 은닉층 대신 Table 1에 나타낸 strided conv 은닉층을 사용하였다. DNN의 학습 단계에서는 mini-batch 구성을 위해 발성의 길이를 3.59 s로 고정하여 사용하였다. 이를 위해 원 발성이 그보다 길 경우 임의로 3.59 s를 잘라 사용하였고, 발성이 더욱 짧을 경우에는 발성을 복제한 뒤 시작점으로부터 3.59 s를 사용하였다. 화자 인증 평가 단계에서는 각 발성을 3.59 s 단위로 잘라 복수의 화자 특징을 추출한 뒤, 이를 평균하여 최종 화자 특징으로 사용하였다.
DNN의 학습 단계에서는 learning rate를 0.001로 지정하였으며, 0.0001의 weight decay를 사용하였다. Mini- batch 크기는 120으로 지정하여 학습하였으며, 최적화 알고리즘은 AMSGrad를 사용하였다. 기타 DNN 학습과 관련된 파라미터는 Reference [4]의 RawNet2와 동일하게 구성하여 모든 실험을 진행하였다.
4.3 결과 분석
Table 2는 베이스라인, FMS, 및 제안한 α-FMS기법을 비교 실험한 결과를 나타낸다. 첫 번째 행은 Raw Net2에서 FMS를 제거하고 strided conv 은닉층을 적용한 시스템인 베이스라인을 나타낸다. 두 번째에서 다섯 번째 행은 Reference [4]에서 제안한 다양한 FMS를 베이스라인에 추가한 시스템을 나타낸다. 마지막으로 다섯 번째와 여섯 번째 행은 각각 α-FMS기법 스칼라 α와 벡터 α를 이용하여 적용한 실험 결과를 나타낸다.
Table 2.
Equal Error Rate (EER) of the baseline and various FMS-based systems. Method column depicts the methods that were applied where Eqs. (1) ~ (4) refer to various FMS techniques proposed in Reference [4] and Eq. (6) refers to the α-FMS method. scalar α-FMS and vector α-FMS both refer to Eq. (6) but the dimensionality of α is different.
| Model | Method | EER (%) |
| baseline[4] | - | 3.00 |
| baseline + add FMS[4] | Eq. (1) | 2.82 |
| baseline + mul FMS[4] | Eq. (2) | 2.66 |
| baseline + add-mul FMS[4] | Eq. (3) | 2.60 |
| baseline + mul-add FMS[4] (RawNet2) | Eq. (4) | 2.56 |
| baseline + scalar α-FMS (proposed) | Eq. (6) | 2.47 |
| baseline + vector α-FMS (proposed) | Eq. (6) | 2.31 |
실험 결과 Eqs. (1) ~ (4) 모두 베이스라인에 적용할 경우 성능이 향상됨을 확인하였다. 스케일 벡터를 더하거나 곱하는 Eqs. (1) ~ (2)의 방식보다, 두 방식을 순차적으로 특징 지도에 적용하는 Eqs. (3) ~ (4) 방식을 통해 더 낮은 동일 오류율을 확인할 수 있었다. 이 중 동일한 스케일 벡터를 특징 지도에 곱한 뒤 더하는 baseline + mul-add FMS가 2.56 %의 동일 오류율을 보임으로써 가장 우수한 성능을 확인할 수 있었다.
본 논문에서 제안한 α-FMS의 경우 α를 스칼라와 벡터로 설정한 두 실험 모두 기존의 FMS 기법들 중 가장 우수한 성능을 보였던 2.56 % 동일 오류율 대비 더욱 향상된 성능을 확인하였다. α를 스칼라로 설정한 결과 2.47 %의 동일 오류율을 확인하였으며, α를 벡터로 설정한 결과 2.31 %의 동일 오류율을 확인하였다. 이를 통해 본 논문에서 분석한 기존 FMS의 한계점과 이를 개선한 α-FMS 기법이 유효하게 DNN 기반 화자 특징 추출기인 RawNet2의 성능을 향상시킴을 검증하였다.
추가적으로, Fig. 3은 제안한 α-FMS 기법이 적용된 심층 신경망의 첫 번째 합성곱 은닉층의 128개의 필터들 중 두 필터와 필터에 주파수 분석을 적용하여 도출한 주파수 응답을 시각화하여 나타내었다. Fig. 3의 위에 나타낸 필터의 경우 약 500에서 1,000 Hz 대역의 주파수 응답을, 아래에 나타낸 필터의 경우 약 2,000에서 2,700 Hz 대역의 주파수 응답을 추출한다. 이를 통해 References [4], References [5]에서 보고된 것과 같이, 각 필터가 다양한 주파수 대역의 가중합을 추출하는 것을 확인하였다.
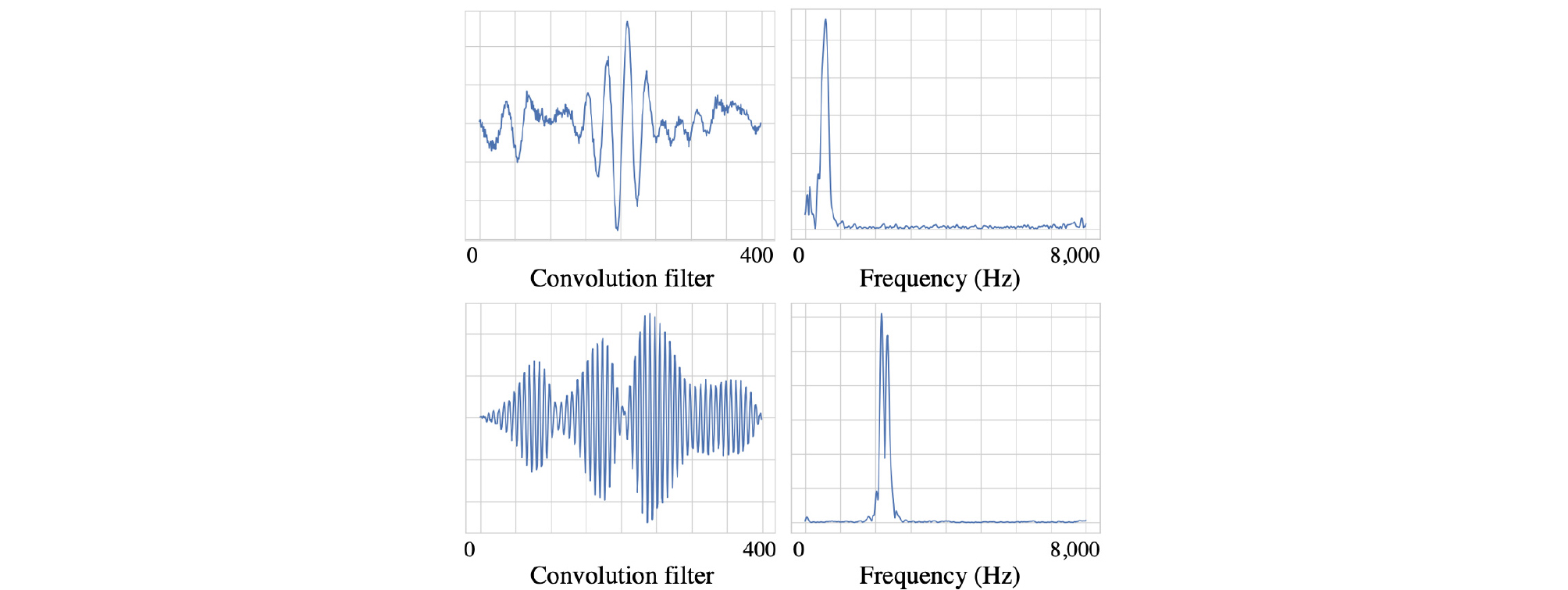
Fig. 3.
(Color available online) Illustration of two filters (left) and their frequency responses (right) of the model, which was trained using the proposed α- FMS technique. The upper filter focuses on 500 Hz ~ 1000 Hz approximately and the lower filter focuses on 2000 Hz ~ 2700 Hz approximately. It demonstrates that the first convolutional filter extracts aggregated frequency responses.
결론
본 논문에서는 기존의 FMS 기법의 한계를 분석하고 이를 보완한 α-FMS 기법을 제안하고 원 음성 화자 인증 시스템에 적용하여 성능을 향상시키는 연구를 수행하였다. 제안한 α-FMS 기법은 DNN의 특징 지도의 분별력을 강화하기 위한 기법으로서 특징 지도의 각 필터에 α를 더한 뒤, 스케일 벡터를 곱하여 동작한다. RawNet2에 적용된 FMS 기법을 제안한 α-FMS 기법으로 대체하여 실험을 진행한 결과, 동일 오류율이 상대적으로 9.8 % 감소한 2.31 %를 확인하였다. 향후 계획으로는 제안한 α-FMS 기법을 다양한 화자 특징 추출기 및 이미지 분야의 DNN에 적용하는 실험을 진행할 예정이다.
