

I. Introduction
II. Concept of self-attention mechanism and its use
2.1 Self-attention mechanism
2.2 Self-attention in speaker verification
2.3 Previous cross attention and masking methods
III. Masked cross self-attentive encoding based speaker embedding
3.1 Model architecture
3.2 Cross self-attention module
IV. Experiments
4.1 Dataset setup
4.2 Experimental setup
4.3 Experimental results
V. Conclusions
I. Introduction
Speaker recognition aims to identify speaker information from input speech. A type of speaker recognition is Speaker Verification (SV). It determines whether the test speaker’s speech is accept or reject compared to the enrolled speaker’s speech.
Traditionally, the Gaussian mixture model with universal background model has been used to encode supervector representing speaker information.[1,2] Next, a joint factor analysis method has been proposed to separate the supervector from the channel and speaker factors.[3] However, these methods required an enormous amount of data for the enrollment. An i-vector has been proposed to solve this issue. It has been used with probabilistic linear discriminant analysis.[4,5]
Since the introduction of deep learning, d-vector have been extracted directly from Deep Neural Networks (DNN).[6] It is trained by using the DNN-based speaker classifier. Then the activations of the last hidden layer are encoded as speaker embedding. In addition, speaker embedding encodings using various DNN-based models have been proposed. In time delay neural network (TDNN)-based model, the x-vector has been proposed. It is a fixed dimensional statistics vector, encoded by using statistical pooling.[7] Among the Convolutional Neural Network (CNN)-based models, ResNet[8] has been used as a representative model for speaker embeddings.[9,10,11,12,13,14]
Attention mechanisms successfully applied to other areas, such as image and language processing.[15,16,17,18,19] In SV, TDNN or CNN model-based speaker embedding encodings using attention mechanism have been proposed.[9,12,20,21,22,23,24,25] Especially, the self-attention mechanism[16] has exhibited high performance in speaker embedding encoding as called Self-Attentive Pooling (SAP).[9,24,25] The SAP is used to encode frame-level features into a utterance-level feature. It focuses on the frames by training interdependence with a context vector. In addition, an SAP-derived method called Multi-Head Attentive Pooling (MHAP) has been proposed to improve performance.[25]
However, these previous methods are focused on training the self-attention in a high-level layer instead of the lower-level layers. In other words, speaker embedding is encoded by using only the output feature of the last pooling layer. It results in decreased low-level features effect in the encoding of a speaker embedding. Therefore, it is difficult to encode the speaker embedding with more discriminative power.
Therefore, we propose a Masked Cross Self-Attentive Encoding (MCSAE). This is a new SAP-derived speaker embedding encoding using ResNet. MCSAE focuses on the features of both the high-level and low-level layers in the self-attention training. Based on Multi-Layer Aggregation (MLA),[14] the output features of each residual layer are used as the input pair of the MCSAE, as shown in Fig. 1. In the MCSAE, the interdependence of each input features is trained by a cross self-attention module. A random masking regularization module also applied to prevent overfitting problem. The MCSAE enhances the weight of frames representing the speaker information. Then, the output features are concatenated and encoded in the speaker embedding. Therefore, a more discrimitive speaker embedding is encoded by using the MCSAE.

We introduce the concept of self-attention and its use in Section 2, describe the proposed MCSAE in Section 3, present the results in Section 4, and present our conclusions in Section 5.
II. Concept of self-attention mechanism and its use
2.1 Self-attention mechanism
The principle of the self-attention mechanism is to focus on training the specific context information. In machine translation, self-attention using scaled dot-product attention and MHAP has been proposed.[16] The scaled dot-product attention is formulated as in Eq. (1).
| $$attention\;(\boldsymbol Q,\;\boldsymbol K,\;\boldsymbol V)=softmax\left(\frac{\boldsymbol Q\boldsymbol K^T}{\sqrt{d_{\boldsymbol K}}}\right)\boldsymbol V.$$ | (1) |
The inputs are comprised of the query (), key (), and value (). To train the relationship between and , scaling is applied to compute similarity using dot product operations on all and elements and each element is divided by ( is the dimension of ). Next, after applying the softmax method for normalization, the weights for are obtained. The more similar is to , the higher its value, more attention will be paid to .
2.2 Self-attention in speaker verification
In SV, SAP, which is applied to TDNN and ResNet- based models, outperforms both the conventional Temporal Average Pooling (TAP) and Global Average Pooling (GAP).[9,24,25]
An input feature of the hidden layer of length is fed into a fully-connected hidden layer to obtain . Given that and a learnable context vector the attention weight is measured by training the similarity between and with softmax normalization as in Eq. (2).
| $${\boldsymbol w}_l=\frac{exp(\boldsymbol h_l^T\cdot\boldsymbol u)}{{\displaystyle\sum_{i=1}^L}exp(\boldsymbol h_i^T\cdot\boldsymbol u)}.$$ | (2) |
Then, the embedding vector is generated by the weighted sum between the normalized attention weights and as in Eq. (3).
| $$\boldsymbol e=\sum_{l=1}^L{\boldsymbol x}_l{\boldsymbol w}_l.$$ | (3) |
Hence, an utterance-level feature focused on each frame is encoded. Additionally, based on this process, the MHAP is conducted by performing several linear projections on each input.[25]
2.3 Previous cross attention and masking methods
Our proposed cross self-attention and masking methods are inspired by the studies conducted by the References [18], References [19], respectively.
In image-text matching, cross attention has been proposed to identify the appropriate text appearing in an input image.[18] The inputs are encoded in both image-text and text-image formulations. Then, the cross attention is applied to both pairs for obtaining more accurate weights than that obtained with just one attention mechanism.
In person re-identification, masking method and attention mechanism have been applied. These are used to solve the problem of the neglected dissimilarities between the source and the target.[19] In the attention process between the source and the target, a masking matrix of integer [1 or -1], according to the label is used.
III. Masked cross self-attentive encoding based speaker embedding
3.1 Model architecture
The proposed model builds on previous research on the speaker embedding encoding based on MLA.[14] The modified ResNet model is trained for speaker classification in an end-to-end training process using several pooling layers.
The proposed model architecture is modified by using a standard ResNet-34 model.[8] It adds MCSAE after each pooling, as shown in Fig. 1 and Table 1. The proposed model has 4 residual layers, 16 residual blocks, and half the number of channels of a standard ResNet-34. Each residual block consists of convolution layers, batch normalizations, and leaky ReLU activation functions (LReLU). Especially, the output features of each residual layer is encoded in the speaker embedding in order, from low-level representation information to high-level representation information.
Table 1.
Proposed model architecture using MCSAE (D: dimension of input feature, L: length of input feature, N: number of speakers, SE: speaker embedding).
The output features (, ) of the two previous pooling layers are used as inputs to the MCSAE. As shown below , which refers to the segment matrix of the attention matrix is generated by applying the random masking regularization module and cross self- attention module as in Eq. (4).
| $${\boldsymbol Z}_i=MCSAE_i({\boldsymbol P}_i,{\boldsymbol P}_{i+1})\;\;\;\;\;\;\;\;\;(0\leq i\leq4).$$ | (4) |
Here, the output of each MCSAE is used to generate an attention matrix of 1×256 size using matrix product calculation in a matmul layer as in Eq. (5).
| $$\boldsymbol M={\boldsymbol P}_1\times{\boldsymbol Z}_1\times{\boldsymbol Z}_2\times{\boldsymbol Z}_3\times{\boldsymbol Z}_4.$$ | (5) |
To match the dimension, an embedding of 1×32 size extracted from the pooling-1 layer is used for the matrix product. Using the matrix allows dimensional matching without increasing the parameters.
In the concat layer, embedding of 1×256 size extracted from the pooling-5 layer is concatenated with attention matrix . The embedding is standard embedding in ResNet without the MCSAE. As a result, an embedding of 1×512 size is encoded as in Eq. (6).
| $$\boldsymbol C=concat(\boldsymbol M,{\boldsymbol P}_5).$$ | (6) |
Finally, the concatenated embedding is encoded into fully- connected layers (fc layer) and output layer representing the speaker classes (output layer). Through this process, a 512-dimensional speaker embedding is extracted.
3.2 Cross self-attention module
The MCSAE employs two main proposed modules: 1) a cross self-attention module and, 2) a random masking regularization module. They aim to encode the segment matrix that generates the attention matrix . The MCSAE is based on the scaled dot-product attention mechanism used in the reference 16. We assume that the feature is a step preceding feature and they are closely related to each other, which is further emphasized by the attention mechanism. Therefore, the cross self-attention module is able to train the interdependence between the feature and feature .
As depicted in Fig. 2, the MCSAE consists of two input pairs performing cross self-attention. The first self- attention input consists of (query, ), (key, ), and (value, ). After the scaled dot-product operation between and , self-attention is performed to the target as in Eq. (7) (so, is the attention target).
| $$attention(\boldsymbol Q,\boldsymbol K,\boldsymbol V)=softmax\;\left(\frac{\boldsymbol Q^T\boldsymbol K}{\sqrt{d_{\boldsymbol K}}}\right)\boldsymbol V^T.$$ | (7) |
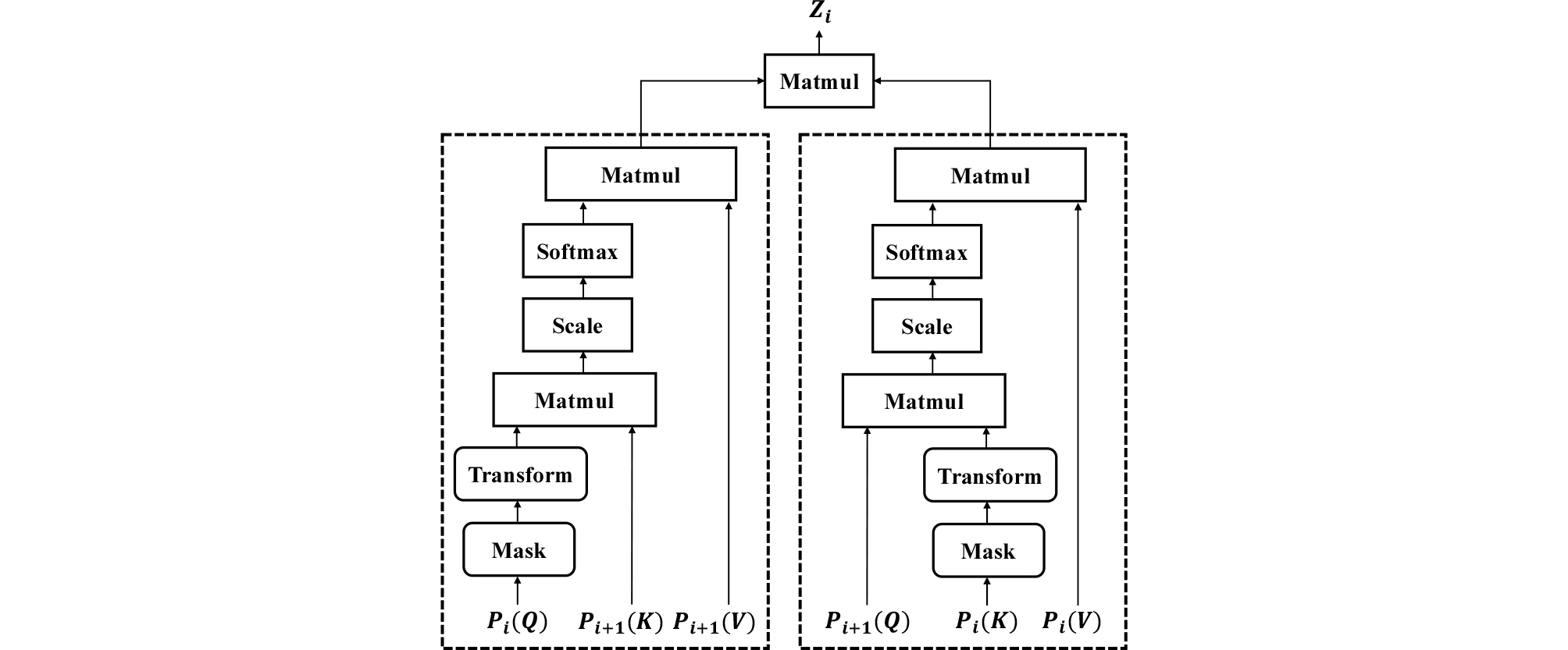
Before the scaled dot-product operation, a random masking regularization module is applied to feature as shown in Fig. 3. Then, a transform layer is applied to masked . Here, an input feature of length is fed into the transform layer to obtain using LReLU activation function with slope 𝜆 as in Eq. (8).
| $${\boldsymbol h}_c=max{\;\{\lambda(\boldsymbol W{\boldsymbol p}_c+\boldsymbol b),(\boldsymbol W{\boldsymbol p}_c+\boldsymbol b)}\}.$$ | (8) |

Next, scaling to the value of ( is the dimension of ) is performed and normalization is applied using the softmax function. The computed matrix is multiplied by and self-attention is finally conducted.
Conversely, the second self-attention input consists of (), (), and (). As is the attention target, the scaled dot attention mechanism is performed the same as earlier. The matrix is encoded using matrix multiplication for the output of the masked cross self-attention as Eq. (9).
| $${\boldsymbol Z}_i=attention_{1^{st}}({\boldsymbol P}_i,{\boldsymbol P}_{i+1},{\boldsymbol P}_{i+1})\times attention_{2^{nd}}({\boldsymbol P}_{i+1},{\boldsymbol P}_i,{\boldsymbol P}_i)^T.$$ | (9) |
3.3 Random masking regularization module
A random masking regularization module is applied for MCSAE, as depicted in Fig. 3. It is inspired by the Reference [19]. It aims to prevent overfitting problem in attention process of the MCSAE layer. The masking map consists of random integers, [0 or 1], according to the value of the adaptive scaling factor (default value is 0.5), which determines the range of masking that is updated by training. As the scaling factor value increases, the range of the masking widens. Then, masking is performed to input the feature and element-wise multiplication. The masked value was filled with zero.
IV. Experiments
4.1 Dataset setup
In this study, we trained the proposed model using the VoxCeleb2 dataset,[26] which contained over 1 million utterances from 5,994 celebrities. These are large-scale text-independent SV datasets collected from YouTube. We evaluated the proposed methods using the VoxCeleb1 evaluation dataset containing 40 speakers and 37,220 pairs of official test protocol.[27]
4.2 Experimental setup
The input feature vectors were 64-dimensional log Mel-filterbank energies of width 25 ms and shift size 10 ms, which were mean-variance normalized over a sliding window of up to 3 s. For each training step, 12 s interval was extracted from each utterance using cropping or padding. In training, we also used the preprocessing method to perform time and frequency masking on input features.
For parameters training, we used the standard stochastic gradient descent optimizer with a momentum of 0.9, a standard cross-entropy loss function, and a weight decay of 0.0001 at an initial learning rate of 0.1, reduced by a 0.1 decay factor on the plateau. Early stopping in 200 epochs was performed with 96 mini-batch size. The initial adaptive scaling factor was 0.5 in the random masking regularization.
Our proposed model was implemented in an end-to-end manner using PyTorch.[28] It does not used additional methods after extracting the speaker embedding such as the References [10], References [14]. From the trained model, we extracted a speaker embedding and evaluated it using cosine similarity metrics: equal error rate (EER, %) performance.
4.3 Experimental results
We experimented with the proposed model using two types of comparisons. The first describes comparisons with previous self-attentive encoding in Table 2. The second describes comparisons with various state-of-the-art encodings in Table 3.
Table 2.
Experimental results compared with previous encodings including SAP (Dim: dimension of speaker embedding).
| Model | Encoding | Dim | EER |
| ResNet-34 | GAP | 256 | 4.57 |
| SAP | 256 | 4.24 | |
| MLA-SAP | 512 | 3.49 | |
| MCSAE (proposed) | 512 | 2.63 |
Table 3.
Experimental results compared with state- of-the-arts methods (*These models used VoxCeleb1 training dataset, which is smaller than the VoxCeleb2 dataset).
| Model | Encoding | Dim | EER |
| ResNet-34[9]* | SAP | 128 | 5.51 |
| VGG[25]* | MHAP | 512 | 4.00 |
| ResNet-34[26] | TAP | 512 | 5.04 |
| ResNet-50[26] | TAP | 512 | 4.19 |
| Thin-ResNet-34[11] | NetVLAD | 512 | 3.57 |
| Thin-ResNet-34[11] | GhostVLAD | 512 | 3.22 |
| ResNet-34l* | MCSAE (proposed) | 512 | 4.18 |
| ResNet-34 | MCSAE (propsoed) | 512 | 2.63 |
Table 2 shows the results according to the modifications of ResNet-34 up to the proposed MCSAE. We applied GAP and SAP methods to ResNet-34. In this case, 256-dimensional speaker embedding was extracted in the last residual layer. Based on MLA, the SAP was performed on the output features of each residual layer (MLA-SAP). Next, the proposed MCSAE was tested. The results showed that the proposed MCSAE performed better than the previous self-attentive encodings.
Table 3 shows the results of the comparison with the state-of-the-art encodings. Here, we focused on speaker embedding encodings using a CNN-based model with the softmax loss function. These models were proposed for using various approaches such as TAP,[26] NetVLAD,[11] and GhostVLAD.[11] In addition, SAP-derived encodings were compared such as MHAP,[25] SAP.[9] The results showed that the proposed MCSAE was comparable to various state-of-the-art methods.
V. Conclusions
In this study, we proposed a new SAP-derived method for speaker embedding encoding called MCSAE. The model was focused on training both high-level and low-level layers in the ResNet architecture, in order to encode a more informative speaker embedding. In the MCSAE, the cross self-attention module improved the concentration of the speaker information by training the interdependence among the features of each residual layer. A random masking regularization module prevented overfitting in the attention process of the MCSAE. The experimental results using the VoxCeleb1 evaluation dataset showed that the proposed MCSAE improved performance when compared with previous self-attentive encoding and state-of-the-art methods.
