

I. 서 론
II. 수영자 탐지 소나에서의 해상실험 데이터 분석
III. 트랙존재확률 기반의 자동 표적 추적 알고리즘
IV. 단일표적추적 IPDAF
4.1 시스템 모델링
4.2 트랙 예측
4.3 트랙 갱신
V. 다중표적추적 LMIPDAF
5.1 트랙 갱신
VI. 해상실험
VII. 모의실험
7.1 모의실험 조건
7.2 모의실험 결과
VIII. 결 론
I. 서 론
연안 군사시설 및 주요 기반시설(항만, 발전소 등)에 대한 수상 및 수중 침투세력의 비대칭 공격으로 인해 수영자 탐지 소나에 대한 중요성은 나날이 증가하고 있다. 수영자 탐지 소나는 잠수부나 수영자와 같은 소형표적을 탐지, 추적 및 식별하여 위협을 판단하는 목적으로 운용되는 능동 소나인데, 잠수부의 신호 특성, 항만과 천해 환경조건에 따른 제약 사항, 선박 이동소음, 해양 포유류 등으로 인한 오경보 및 오탐지와 같은 문제들로 인해 기술적인 측면에서 많은 어려움이 있다. 수영자 탐지 소나를 개발함에 있어서 빔형성, 신호처리(탐지/추적/식별) 등 다양한 핵심기술들이 요구되는데, 본 논문에서는 수영자 탐지 소나의 해상실험 데이터를 분석하였고, 분석한 내용을 토대로 클러터 환경에서 자동으로 표적에 대한 트랙을 초기화하고 관리 및 추적하는 자동 표적 추적 알고리즘에 대한 내용을 다루었으며, 해상실험 데이터를 이용하여 성능을 분석하였다.
클러터 환경에서 일반적인 표적추적 알고리즘은 예측된 트랙 위치를 중심으로 유효측정영역을 설정하여, 유효측정영역 내 존재하는 가장 가까운 정보를 사용하는 NNF(Nearest Neighbor Filter),[1] 가장 신호세기가 높은 정보를 사용하는 SNF(Strongest Neighbor Filter),[2] 유효측정영역 내 모든 정보들에 대해 확률적 가중치를 부여하여 사용하는 PDAF (Probabilistic Data Association Filter)[3],[4] 등이 있다. 그러나 이 방법들은 현존하는 트랙들이 표적에 대한 것인지 아닌지를 판별하기 위한 트랙 스코어와 같은 수단을 제공하지 않아서 효율적으로 표적을 추적하기에는 무리가 있다.
트랙 존재성에 대한 정보를 제공할 수 없다는 제약을 극복하기 위해 D. Musicki는 기존 PDAF에 표적 존재유무에 대한 가설을 마르코프 연쇄(Markov Chain)로 모델링하고, 유효측정영역 내 모든 탐지정보들을 이용하여 트랙존재확률(Track Existence Probability)을 산출하여 이를 트랙 초기화, 확정, 제거 등의 트랙관리 알고리즘에 적용할 수 있는 단일표적추적 IPDAF (Integrated Probabilistic Data Association Filter)[5],[6]를 제안하였다. 그런데 다수의 표적들이 서로 근접한 상황에서는 단일표적추적 알고리즘을 적용 시 성능이 저하되는데, 이에 대한 해결을 위해 측정치와 트랙 간 모든 결합사건들을 고려하는 최적 기법인 JIPDAF (Joint Integrated Probabilistic Data Association Filter)[7]가 제안되었다. 하지만 측정치와 트랙 개수 증가에 따라 연산량이 많아진다는 단점이 있는데, 이를 보완하기 위해 LMIPDAF(Linear Multi target Integrated Probabilistic Data Association Filter)[8],[9]를 제안하였다. LMIPDAF는 트랙 주변의 다른 표적들을 클러터로 간주하는 ‘등가 클러터’ 개념을 사용하는 것이 큰 특징이다.
본 논문에서는 추적 알고리즘의 성능을 향상시키기 위해 해상실험을 통해 얻은 데이터를 분석하고 클러터 감소 알고리즘을 적용하여 노이즈 및 오탐지 정보를 제거하였다. 또한 클러터가 존재하는 수영자 탐지 소나에서의 자동 표적 추적 알고리즘을 구성함에 있어서 트랙존재확률 기반의 알고리즘을 적용하였는데, 뒷장에서 트랙존재확률을 이용하여 트랙을 관리하는 방법과 표적추적 알고리즘인 단일표적추적 IPDAF, 다중표적추적 LMIPDAF에 대해 상세히 다루었다. 그리고 해상실험 데이터를 이용한 다중표적추적 LMIPDAF 기반 자동 표적 추적 알고리즘 성능 분석과 함께 모의실험 데이터를 이용한 각 알고리즘의 성능을 비교 및 분석하여 수영자 탐지 소나에 적용하기에 적합함을 보였다. 또한 적용한 자동 표적 추적 알고리즘은 수영자 탐지 소나, 기뢰회피소나와 같은 능동센서를 사용하는 다양한 분야에서 활용할 수 있을 것으로 기대된다.
II. 수영자 탐지 소나에서의 해상실험 데이터 분석
잠수부나 수영자에 대한 추적 성능을 향상시키기 위해서는 표적 정보 이외에 거짓정보인 클러터가 최소화되어야 하며, 각 표적에 해당하는 탐지정보는 최대 한 개만 존재해야 높은 신뢰도의 자동 표적 추적 결과를 산출 할 수 있다. 아래의 Fig. 1은 수영자 탐지 소나를 이용하여 얻은 해상실험 데이터에서 운용자가 설정한 문턱값을 이용한 탐지결과를 나타낸 것이다. 탐지문턱값은 탐지확률과 오탐지확률의 함수인 Receiver Operating Curve를 이용하여 결정하는데 통상적으로 탐지확률은 50 % 이상 오탐지확률은 1 % 이하로 설정한다. 수영자 탐지 소나의 경우 천해 잔향에 의한 클러터가 매우 높은 환경에서 소형 표적을 탐지하는 상황이므로 클러터에 의한 오탐지확률이 높더라도 표적 탐지 확률을 우선적으로 고려하여 탐지문턱을 설정한다. 잔향에 의한 클러터는 정적인 탐지 패턴과 표적추적 정보에 의한 동적인 패턴을 활용하여 추가적으로 제거하여 오경보확률을 감소하는 기법을 사용한다.
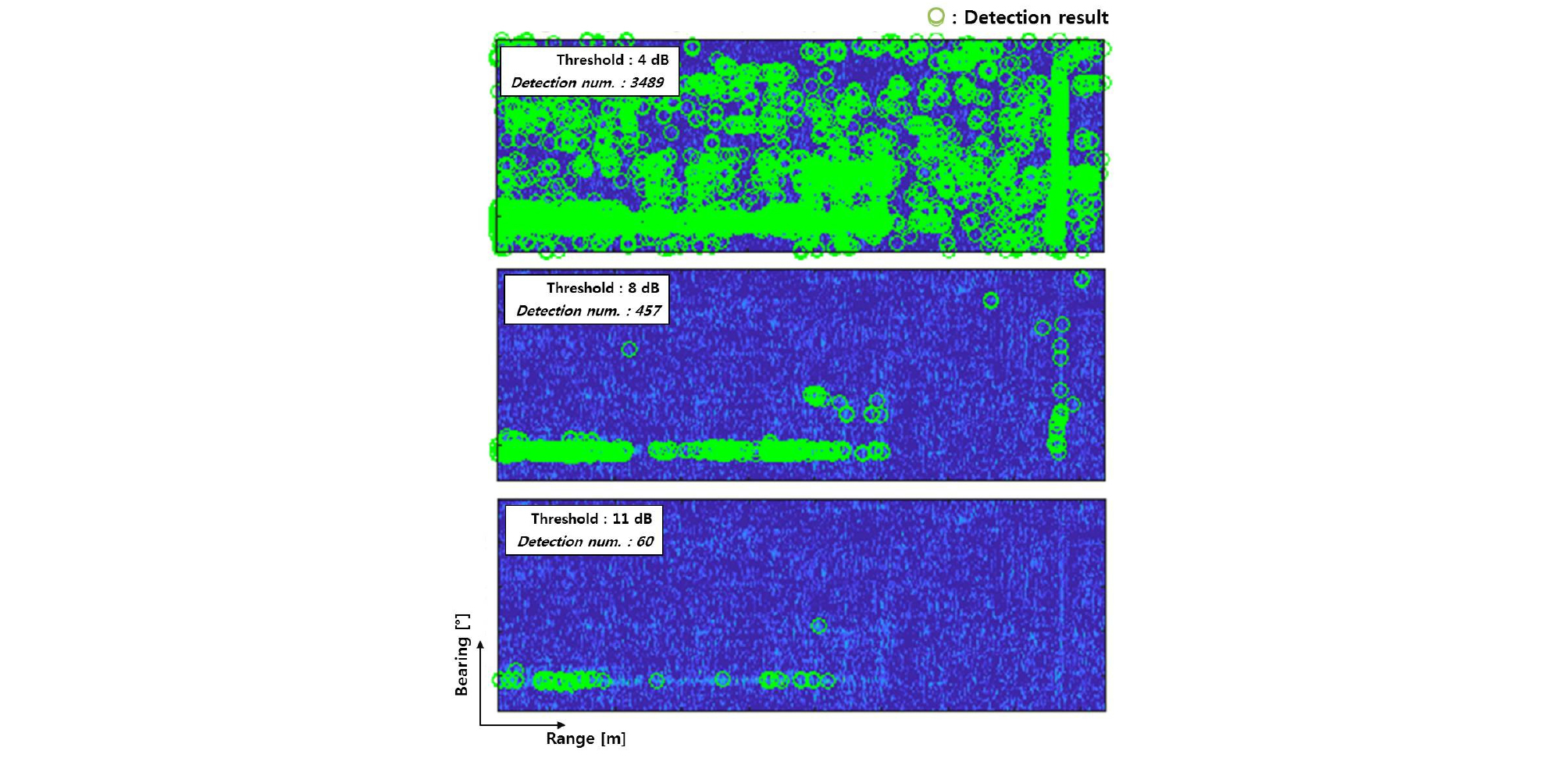
문턱값만을 이용한 표적 탐지의 경우 Fig. 1의 결과와 같이 문턱값 수치에 따라 탐지 결과가 크게 변동함을 알 수 있다. 따라서 신뢰도 높은 탐지 결과를 도출하기 위해서는 표적 및 수중의 환경적 특성을 고려한 알고리즘을 적용하여 결과를 도출해야 한다.
문턱값을 설정하여 표적을 탐지하는 알고리즘은 해저지형 및 수중, 수상 운동체에서 반사되어 들어온 신호를 표적과 구분하기 힘들고, 주변 노이즈 및 외란에 취약한 탐지 방법이므로, 클러터 맵을 구하여 규준화한 빔출력 매치트 필터링에 대해 문턱값을 이용한 표적 탐지 후 클러스터링, 디클러터링 및 오탐지율 감소 탐지 알고리즘을 추가적으로 적용하여 표적 정보 외에 존재하는 클러터를 제거하는 선행 작업이 필요하다.
문턱값만을 설정하여 표적을 탐지하는 경우 위의 Fig. 1과 같이 다수의 탐지정보가 산출되는데, 이는 탐지하고자 하는 잠수부가 아닌 물체에서 반사된 값으로, 추적에 불필요한 정보가 혼재되어 있다. 따라서 이러한 오탐지 정보를 제거하기 위해 클러스터링 작업을 수행한다. DBSCAN(Density-Based Spatial Clustering of Algorithm with Noise) 알고리즘은 탐지 결과의 밀도를 측정하여 동일 표적에서의 탐지 값을 그룹화하기 위한 기법으로,[10] 이를 이용하여 탐지정보의 유사도를 확인 후 그룹으로 묶어준다. 클러터, 수영자, 물고기떼, 함정 표적 등의 반사파 특성을 이용하여 그룹으로 설정한다.
그룹으로 묶이지 않은 표적은 DBSCAN 알고리즘의 요소인 코어 또는 보더에 속하지 않음을 의미하므로 표적 정보에서 제외시킨다. DBSCAN을 통해 산출된 각 그룹은 특정 크기를 띄고 있는데, 일반적인 잠수부의 크기를 고려하여 이에 부합하는 크기의 그룹은 남기고, 이외의 값을 제거하는 디클러터링 작업을 수행한다. 디클러터링을 통해 제거된 데이터에서 노이즈에 의한 오탐지 확률을 줄이기 위해 CFAR (Constant False Alarm Rate) 탐지 알고리즘을 적용한다. CFAR는 표적 탐지 시 오탐지를 줄이기 위해 탐지된 표적과 주변의 세기를 비교하여 표적의 여부를 판단하는 알고리즘이다.[11]
위에서 설명한 일련의 과정들을 통해 산출한 탐지정보의 결과는 Fig. 2에서 확인할 수 있다.
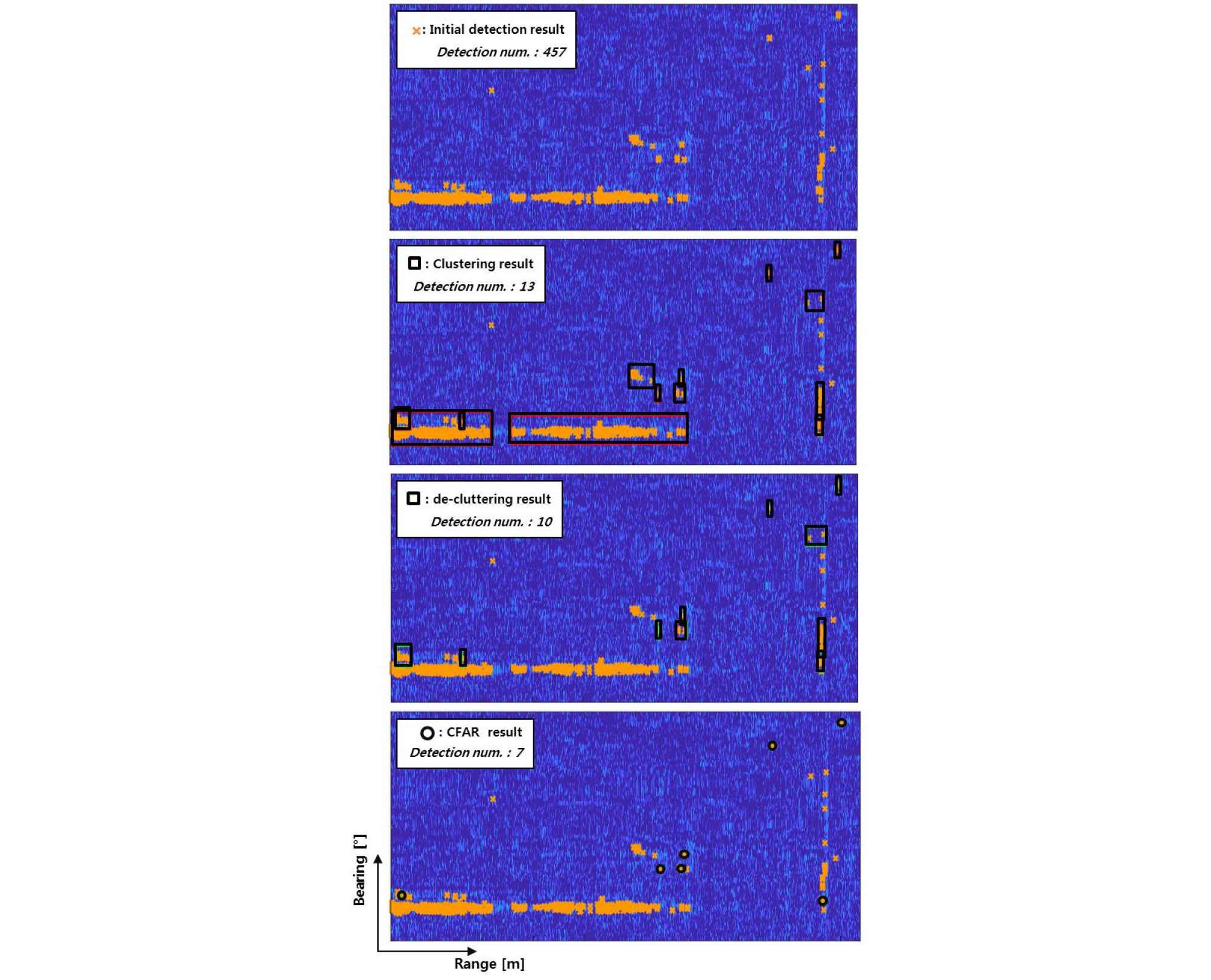
문턱값만을 이용하여 표적을 탐지하였을 경우 457개의 탐지정보가 산출되었으나, 각 알고리즘을 적용 후 최종적으로 산출된 탐지정보의 개수는 7개이다. 수영자나 함정 등의 표적탐지 성능은 유지하면서 잔향에 의한 클러터와 함정 이동시 스크류에 의한 버블로 생기는 항적을 제거할 수 있다. 이는 수중배경소음, 해저 잔향, 항적 등 다이버가 아닌 클러터에 의한 탐지정보가 제거된 것으로, 추적 성능 향상을 위한 선행 작업으로서의 필요성을 보여준다.
III. 트랙존재확률 기반의 자동 표적 추적 알고리즘
수영자 탐지 소나는 고해상도의 탐지 능력을 보유한 능동소나로서 이로 인해 표적 탐지정보 추출을 위해 문턱값을 낮추게 되면 오탐지가 다수 발생할 수 있다. 또 해상실험 데이터를 분석한 바와 같이 탐지 단에서의 다양한 방법을 통하여 다수의 클러터가 제거 가능하지만, 일부 클러터에 대해서는 제거하기 어려우며, 클러스터링을 통하여 동일 표적에 대한 탐지정보를 그룹화 하지만 한계가 있다. 이처럼 수영자 탐지 소나와 같이 클러터가 존재하는 환경에서 자동으로 표적 탐지정보를 찾아서 추적하는 시스템을 구성하기 위해서는 트랙스코어와 같은 트랙평가수단이 요구된다. 본 논문에서는 서론에서 소개한 대표적인 트랙평가수단인 트랙존재확률 기반의 알고리즘을 적용하였다.
Fig. 3은 수영자 탐지 소나에서의 트랙존재확률 기반의 자동 표적 추적 알고리즘 구조를 나타낸 것이다. 크게 트랙 초기화, 확정, 제거, 합병을 수행하는 트랙관리 알고리즘과 트랙 예측 및 갱신을 수행하는 표적추적 알고리즘으로 구성되는데, 본 장에서는 트랙관리 알고리즘을 소개하였고, 표적추적 알고리즘에 대한 내용은 4장에서 단일표적추적 IPDAF, 5장에서 다중표적추적 LMIPDAF를 상세히 다루겠다.
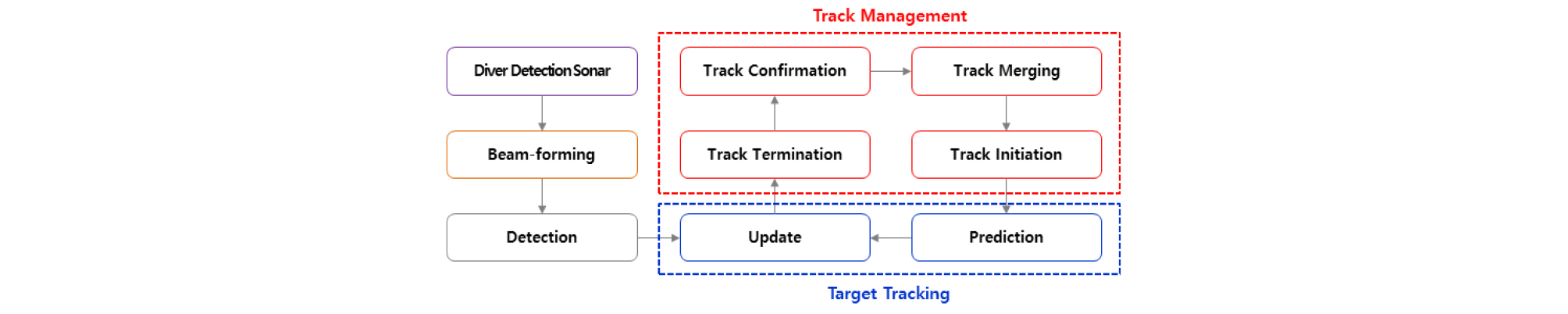
먼저 트랙 초기화는 매 스캔마다 획득된 탐지정보들을 이용하여 트랙의 초기치를 산출하여 트랙 궤적을 생성하는 단계로, 본 논문에서는 연속된 두 스캔에서의 탐지정보들을 이용하여 트랙의 초기 상태변수 및 오차공분산을 산출하는 Two-Points 트랙 초기화를 적용하였다. Eq. (1)은 스캔 k에서 i번째 탐지정보 zk,i와 스캔 k−1에서 j번째 탐지정보 zk-1,j 간 속력이 최대속력 문턱값 이내 인 경우 초기 상태변수 와 오차공분산 를 나타낸 것이다. 여기서 탐지정보 zk,i는 수영자 탐지 소나의 탐지 결과인 2차원 상에서의 위치 zk,i=[xk,iyk,i]T, ΔT는 연속된 두 스캔 사이의 시간 간격, 즉 샘플링 타임, Rk,i는 스캔 k에서 i번째 측정치의 측정잡음 공분산을 나타낸다.
Table 1은 스캔 k−1과 스캔 k의 탐지정보들 간 산출된 속력을 나타낸 것으로, 최대속력 문턱값을 수영자 또는 잠수부의 속력, 그리고 측정잡음 등을 고려하여 5 kts로 설정하였을 때 가능(회색 셀) 또는 불가능(흰색 셀)한 초기화 트랙들의 예를 보여준다.
Table 1. Speed for detection data of 2 scans.
| Scan k | |||||
| 1th | 2nd | 3rd | 4th | ||
| Scan k-1 | 1th | 0.8 | 28 | 160 | 253 |
| 2nd | 27 | 0.9 | 154 | 233 | |
| 3rd | 111 | 83 | 166 | 183 | |
이와 같이 최대속력 문턱값 이내의 조건을 만족하여 초기화된 트랙은 Fig. 4와 같이 초기에 임시 트랙으로 구분된다. 그 후 표적추적 알고리즘을 통해 산출된 트랙존재확률이 확정 문턱값 이상이면 확정 트랙으로 분류하여 트랙을 계속 유지하고(트랙 확정), 트랙존재확률이 제거 문턱값 미만이면 제거트랙으로 분류하여 삭제한다(트랙 제거). 이와 같이 트랙 상태를 분류함으로써 클러터 환경과 같이 다수 트랙들이 발생되는 상황에서도 효율적으로 트랙을 관리하며 시스템의 연산량을 줄일 수 있다.

표적추적 알고리즘을 통해 유효측정영역 내에 포함된 유효 탐지정보는 트랙 초기화 시 미사용 탐지정보로 분류 가능하지만, 매 스캔 트랙 초기화를 수행하다 보면 동일 표적에 대한 다수 트랙들이 발생할 수 있다. 이러한 트랙들은 불필요한 연산으로 시스템의 과부하를 발생시킬 수 있기 때문에 유사한 상태변수 추정치를 갖는 트랙들을 하나의 트랙으로 합병하는 트랙 합병을 수행함으로써 해결 가능하다. 트랙 합병은 모든 존재하는 트랙들 에 대해 두 개씩 조합하여 Eq. (2)의 만족 여부를 확인하고, 만족 시 두 트랙 중 오차공분산의 행렬식이 작은 트랙을 유지하고, 나머지 트랙은 제거한다. Eq. (2)에서 와 는 각각 스캔 k에서 갱신된 각 트랙 τ1과 τ2에 대한 상태변수 추정치 및 오차공분산, T는 전치행렬 그리고 τm은 합병 문턱값을 나타낸다.
| $$(\widehat X_{k\vert k}^{\tau1}-\widehat X_{k\vert k}^{\tau2})^T(P_{k\vert k}^{\tau1}+P_{k\vert k}^{\tau2})^{-1}(\widehat X_{k\vert k}^{\tau1}-\widehat X_{k\vert k}^{\tau2})\leq\tau_m.$$ | (2) |
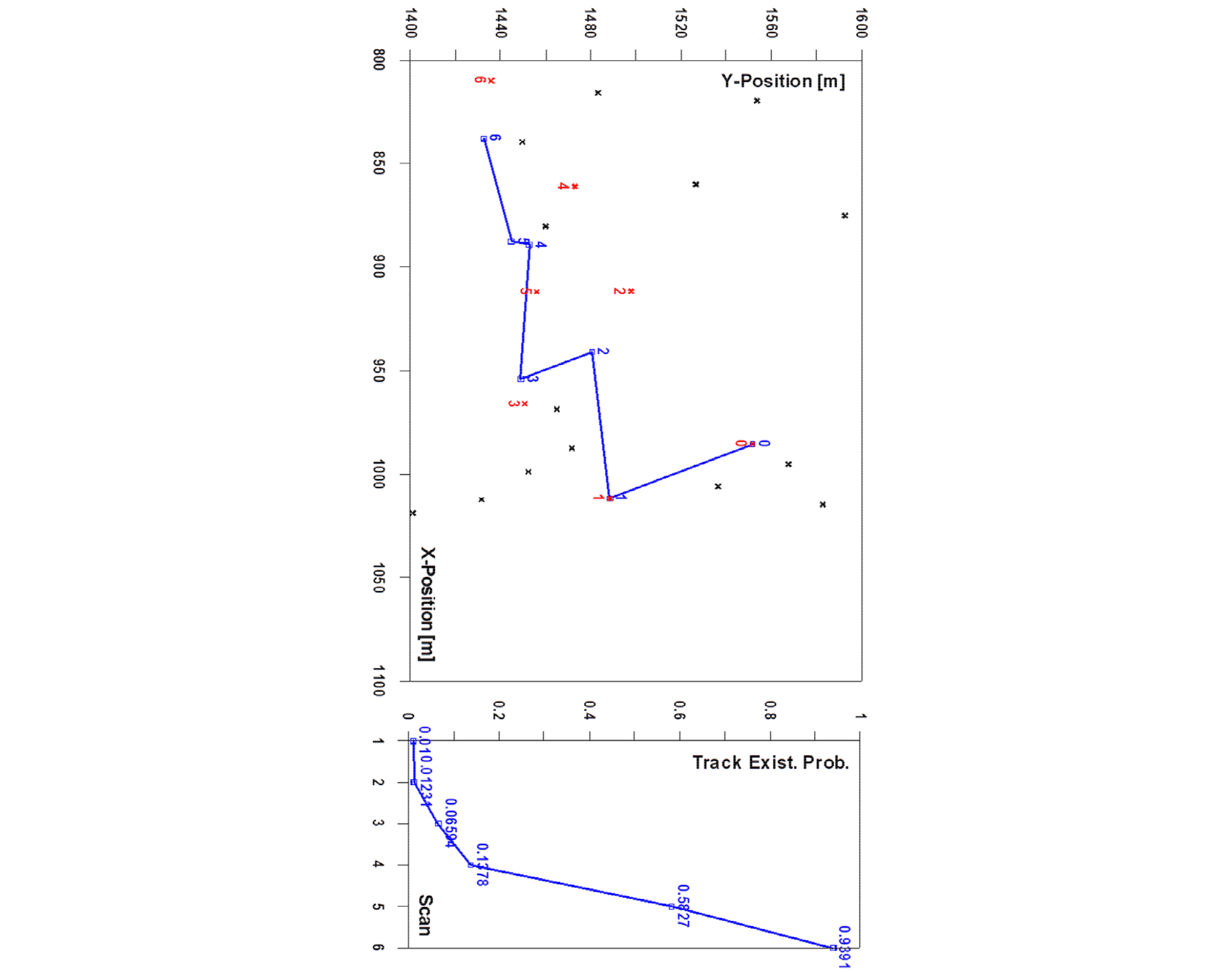
Fig. 5는 단일표적추적 IPDAF에 트랙관리 알고리즘을 적용한 자동 표적 추적 시뮬레이션의 한 예로, 사용가능한 탐지정보들을 이용하여 트랙을 초기화 한 후 추적하는 일련의 과정을 보여준다. 좌측 그림에서 수치가 없는 점은 클러터, 수치가 있는 점은 표적 탐지정보 그리고 수치는 각 정보의 스캔을 나타내는데, 스캔 0과 1의 탐지 정보를 연결하여 Two- Points 트랙 초기화로 트랙이 생성된 후 근방의 탐지정보들을 이용하여 트랙정보를 쇄신하게 된다. 쇄신 과정 중 트랙 위치/속력 정보뿐만 아니라 우측 그래프의 트랙존재확률을 함께 산출하게 되는데, 만약 매 스캔 유효한 탐지정보 존재 시 트랙존재확률은 계속 증가하여 지속적으로 트랙을 유지하면서 추적하는 것을 볼 수 있다. 산출된 트랙존재확률은 트랙 확정 또는 제거와 같은 트랙관리를 수행하는데 사용된다.
IV. 단일표적추적 IPDAF
본 장에서는 자동 표적 추적 알고리즘을 구성함에 있어서 요구되는 트랙평가수단으로 트랙존재확률 기반의 알고리즘인 IPDAF[5],[6]에 대해 다루고자 한다. IPDAF는 유효측정영역 내 모든 탐지정보들을 이용하여 이를 확률적으로 결합하여 트랙정보를 갱신하는 PDAF[3],[4]에 표적 존재유무에 대한 2가지 가설을 마르코프 연쇄(Markov Chain)로 모델링하고 각 가설에 대한 사후 확률을 산출하는 방법이다.
4.1 시스템 모델링
IPDAF에 대해 설명하기에 앞서 시스템 모델링을 설명하겠다. 본 논문의 표적추적 대상인 수영자 탐지 소나에서의 수영자의 상태변수는 2차원 상에서의 위치 및 속력으로 구성되며, 스캔 k에서의 표적의 상태변수는 Xk로 표현되고, 와 같다. 동역학 모델링은 다음과 같이 전개되는데, 여기서 Fk,k−1은 상태변수 천이행렬로 등속직선운동을 한다고 가정하였고, Eq. (3)에 제시되어 있으며, vk는 평균이 0이고 공분산 행렬이 Qk,k−1인 백색 가우시안(White Gaussian) 잡음이다.
| $$X_k=F_{k,k-1}\;X_{k-1}\;+v_k\;where\;F_{k,k-1}=\begin{bmatrix}1&\Delta T\\0&1\end{bmatrix}.$$ | (3) |
다음으로 표적에 대한 탐지정보 모델링은 Eq. (4)와 같이 수영자 탐지 소나에서 탐지되는 거리와 진북기준 방위 로 구성되며 , 여기서 는 평균이 0이고 공분산이 인 백색 가우시안 잡음을 나타낸다.
| $$z_k^{r\theta}={\lbrack r_k\theta_k\rbrack}^T=h_k(X_k)+w_k^{r\theta}.$$ | (4) |
4.2 트랙 예측
IPDAF는 트랙 존재유무에 대해 해당 트랙이 존재한다는 가설 χk와 존재하지 않는다는 가설 를 고려하여 마르코프 연쇄(Markov Chain) 모델을 적용하는데, 스캔 k−1에서 k로 예측 시 각 가설에 대한 상태 천이확률은 다음과 같다.
Eq. (5)에서 각 성분은 p11+p12=p21+p22=1을 만족하고, 스캔 k에서 사전 트랙존재확률 은 다음과 같이 스캔 k−1에서 산출된 사후 트랙존재확률과 상태 천이확률을 이용하여 계산된다.
| $$\textstyle\psi_{k\vert k-1}=p_{11}\psi_{k-1\vert k-1}+p_{21}(1-\psi_{k-1\vert k-1}).$$ | (6) |
스캔 k−1에서 k로 예측된 상태변수 추정치 및 오차공분산은 로 스캔 k−1에서 유효 탐지정보를 이용하여 갱신된 상태변수 추정치 및 오차공분산을 로 정의하면, 상태변수 예측은 다음과 같이 얻을 수 있다.
| $$\textstyle\begin{array}{l}{\overline X}_{k\vert k-1}=F_{k,k-1}{\overbrace X}_{k-1\vert k-1}\\P_{k\vert k-1}=F_{k,k-1}P_{k-1\vert k-1}F_{k,k-1}^T+Q_{k,k-1}.\end{array}$$ | (7) |
4.3 트랙 갱신
칼만필터 기반의 추적필터는 NDS(Normalized Distance Squared) 개념을 적용하여 유효 탐지정보를 선별하는데, NDS는 유효측정영역 중심인 트랙 예측위치와 탐지정보 간 거리인 잔차 및 이에 대한 공분산을 이용하여 산출된 확률적인 거리로 정의된다. Eq. (8)은 스캔 k에서 i번째 탐지정보인 zk,i의 NDS를 이용하여 유효 탐지정보 여부를 판별하는 조건을 나타낸 것이다. 여기서 τd는 유효측정영역에 대한 문턱값으로 2차원 상에서의 표적을 탐지하는 소나 특성을 고려하여 대략 3-σ 게이트로 설정하였다.
| $$\textstyle(z_{k,i}-H_k{\overline X}_{k\vert k-1})^TS_{k,i}^{-1}(z_{k,i}-H_k{\overline X}_{k\vert k-1})\leq\tau_d.$$ | (8) |
앞서 탐지정보에 대해 거리 및 진북기준 방위로 모델링하였는데, 본 논문에서는 트랙 갱신에서 활용하는 과정에서 2차원 상에서의 위치로 변환하여 사용하며, 이에 따른 탐지정보 및 이에 대한 공분산은 다음 식을 통해 변환된다.
Eq. (8)을 통해 선별된 유효 탐지정보들이 mk>0개 존재하는 경우, 표적 탐지정보가 존재하고 mk−1개의 클러터가 존재하는 사건과 mk개의 모든 탐지정보들이 클러터일 사건을 고려하여 산출된 자료결합 확률은 Eq. (10)과 같으며, 모든 자료결합 확률의 합은 1이 된다.
| $$\beta_{k,i}=\left\{\begin{array}{l}\frac{P_DP_G{\displaystyle\frac{P_{k,i}}{\lambda_{k,i}}}}{1-\delta_k}\;i=1,\;\cdots,\;m_k\\\frac{1-P_DP_G}{1-\delta_k}\;i=0\end{array}\right..$$ | (10) |
여기서 PD,PG는 각각 표적 탐지 확률과 유효측정영역 내 존재할 확률을 나타내고, λk,i는 스캔 k에서 i번째 탐지정보의 클러터 공간밀도, 그리고 pk,i는 탐지정보 zk,i에 대한 확률밀도함수를 나타낸다.
최종 트랙평가수단인 사후 트랙존재확률은 Eq. (6)의 사전 트랙존재확률과 우도비(likelihood ratio)에 관련된 Eq. (10)의 δk을 이용하여 다음과 같이 산출된다.[5],[6]
| $$\psi_{k\vert k}=\frac{(1-\delta_k)\psi_{k\vert k-1}}{1-\delta_k\psi_{k\vert k-1}}.$$ | (11) |
또 산출된 자료결합 확률과 유효 탐지정보를 이용하여 갱신된 최종 상태변수 추정치와 오차공분산은 Eq. (12)와 같은데, 이는 Eq. (10)에서 산출한 자료결합 확률을 가중치로 하여 결합되는 것을 의미하고, 각 성분 는 i>0에 대해서는(i번째 탐지정보가 표적탐지일 경우) Eq. (13)과 같이 칼만필터의 쇄신 단계로 추정되며, i=0에 대해서는(모든 탐지정보가 클러터일 경우) Eq. (14)와 같이 칼만필터의 예측 단계 추정치를 그대로 사용한다.
| $$\begin{array}{l}{\widehat X}_{k\vert k,0}={\overline X}_{k\vert k-1}\\P_{k\vert k,0}=P_{k\vert k-1}\end{array}.$$ | (14) |
V. 다중표적추적 LMIPDAF
4장에서 설명한 IPDAF는 유효 탐지정보가 표적 또는 클러터로부터 발생된 것이라고만 가정한다. 즉 다른 표적들로부터 발생되었을 가능성을 전혀 고려하지 않는데, Fig. 6과 같이 서로 근접한 표적들이 공통의 탐지정보를 공유하게 되는 다중표적추적 상황에서는 적용하기에 적합하지 않다.
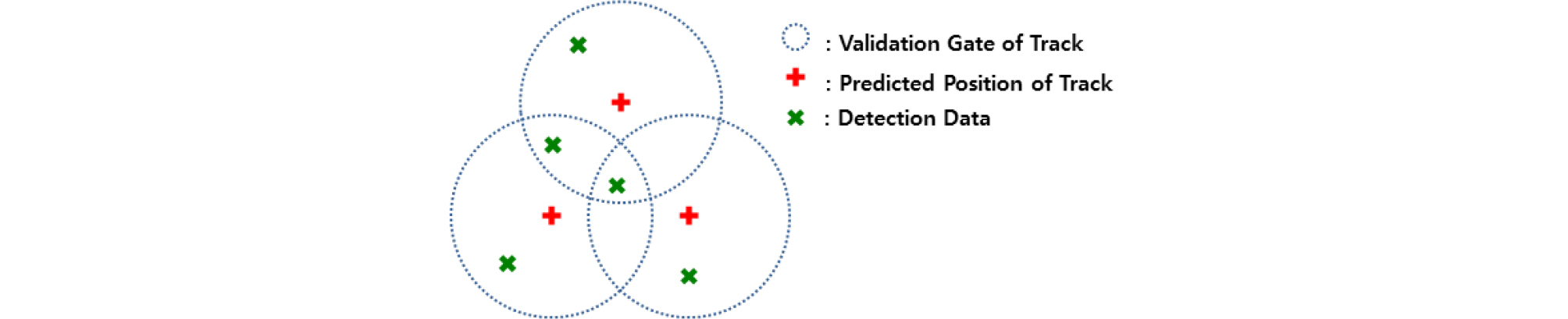
다중표적추적 문제를 해결하기 위해 여러 접근들이 제안되었는데, [7],[8],[9] 그 중 하나는 각 탐지정보와 각 트랙들에 대해 모든 가능한 결합사건들을 고려하는 JIPDAF[7]가 있다. JIPDAF는 발생 가능한 모든 결합사건들을 고려하기 때문에 최적 기법으로 알려져 있지만, 탐지정보와 트랙 개수 증가에 따라 기하급수적으로 연산량이 증가하고 복잡해진다는 단점이 있다. 이러한 단점을 보완하기 위해 준최적이긴 하지만 탐지정보와 트랙 개수 증가에 따른 계산적인 복잡성을 줄이기 위해 LMIPDAF[8],[9]가 제안되었다. LMIPDAF는 다른 트랙들로부터 기인된 탐지정보를 클러터로 간주하여 이에 대한 확률적 가중치를 클러터 공간밀도에 부여하는 방법이다. 즉 트랙으로부터 트랙존재확률 산출 시 기존의 클러터 공간밀도에 다른 트랙들로부터 기인될 확률분포를 포함하게 되는데, 이러한 이유로 전형적인 다중표적추적 알고리즘에서 사용되는 측정치 할당 부분이 필요치 않게 되고, 연산량 측면에서 큰 이득을 얻을 수 있다.
실제 수영자 탐지 소나에서 탐지되는 대상들이 수영자 외에도 선박, 어류, 해양 포유류, 부유물 등 다양한 종류의 표적들이 존재할 것으로 판단되며, 여러 트랙들이 서로 겹치는 다중표적추적 상황이 빈번하게 발생될 것으로 예상된다. 이에 본 논문에서는 다중표적추적 상황과 클러터가 존재하는 수영자 탐지 소나 특성을 고려하여 실시간 처리가 가능한 다중표적추적 알고리즘인 LMIPDAF를 적용하였다.
5.1 트랙 갱신
LMIPDAF의 핵심은 클러터 공간밀도를 다른 트랙들로부터 기인된 사전 탐지정보 확률분포를 포함하여 수정하는 것이다.
먼저 선택된 탐지정보가 표적 또는 클러터로부터 발생되었다는 가정 하에 스캔 k에서 i번째 탐지정보가 트랙 τ의 탐지일 사전 확률 는 다음과 같은데, 탐지정보 에 대한 클러터공간밀도 λk,i 대신 트랙 τ에 대한 탐지정보 의 클러터공간밀도 를 사용함으로써 다른 트랙들로부터 기인하였을 경우를 고려한다.
| $$P_{k,i}^\tau\approx P_D^\tau P_G^\tau\psi_{k\vert k-1}^\tau\frac{p_{k,i}^\tau/\lambda_{k,i}^\tau}{{\displaystyle\sum_{j=1}^{m_k^\tau}}p_{k,j}^\tau/\lambda_{k,j}^\tau}.$$ | (15) |
여기서 는 각각 트랙 τ의 탐지 확률과 게이팅 확률을 나타내고, λk,i는 스캔 k에서 i번째 탐지정보의 클러터 공간밀도, 는 탐지정보 에 대한 확률밀도함수를 의미한다.
Eq. (15)의 사전 확률을 이용하여 클러터 공간밀도를 수정한 최종 결과는 다음과 같으며,[8],[9] 다음 수식은 탐지정보 가 다른 트랙의 탐지일 사전 확률이 높으면 클러터공간밀도가 크게 부여되고, 반대의 경우 작게 부여됨을 의미한다.
| $$\widetilde\lambda_{k,i}^\tau=\lambda_{k,i}+\sum_{\begin{array}{c}\sigma=1\\\sigma\neq\tau\end{array}}^T+p_{k,i}^\sigma\frac{P_{k,i}^\sigma}{1-P_{k,i}^\sigma}.$$ | (16) |
이 수정된 클러터 공간밀도 를 통해 다중표적상황 문제를 간단하게 고려할 수 있으며, 자료결합 확률 및 사후트랙존재확률, 상태변수 추정치 등의 수식은 앞 장의 IPDAF Eqs. (10) ~ (14)와 동일하지만, Eq. (10)에서 λk,i 대신 가 사용된다.
VI. 해상실험
본 장에서는 해상실험 데이터를 이용하여 다중표적추적 LMIPDAF 기반 자동 표적 추적 알고리즘 성능을 분석하고자 한다. Fig. 7은 해상실험 탐지정보로서 대략 10여분의 데이터를 수집한 것으로 표적은 화살표 방향으로 기동하고 있다.
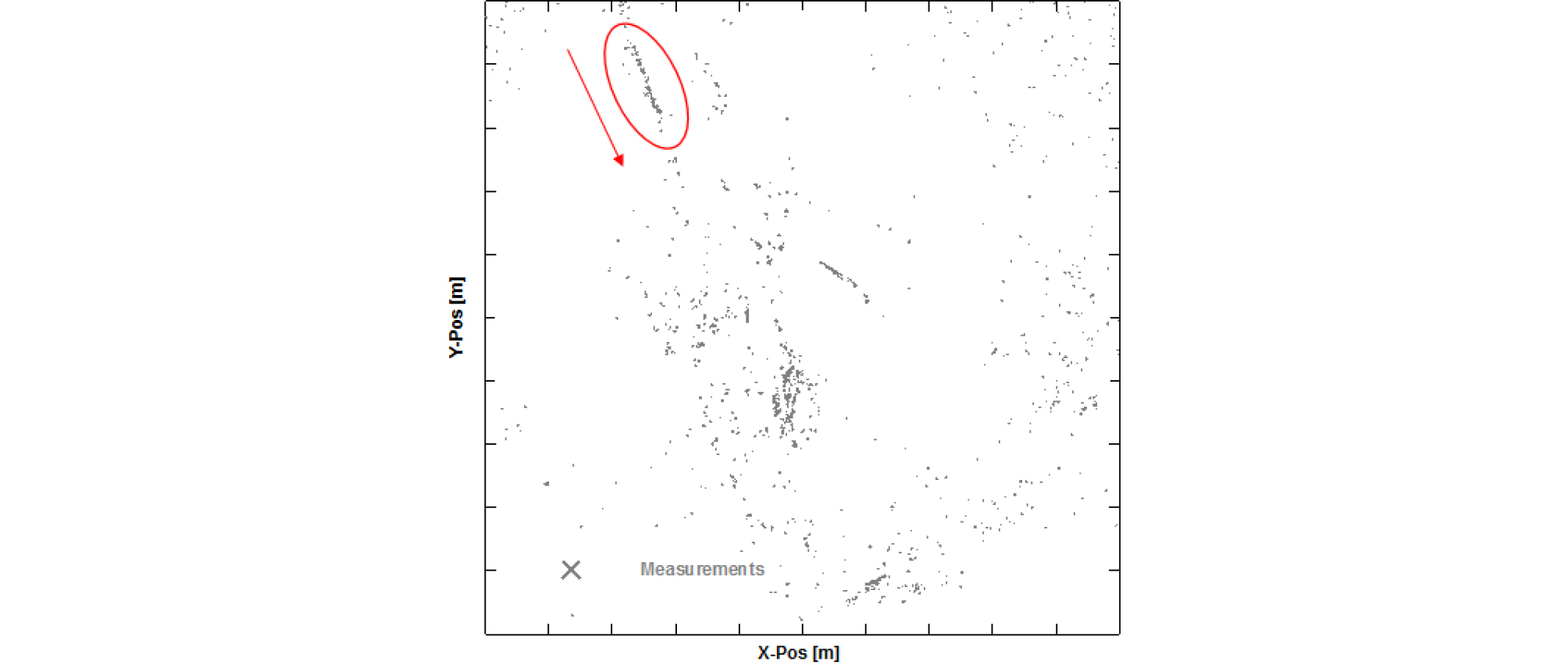
Fig. 8은 탐지 단에서의 클러터제거 알고리즘을 적용한 탐지정보 개수를 나타낸 것인데, 매 스캔 평균 23개의 탐지정보가 획득되었다. 자동 표적 추적 알고리즘의 결과는 Figs. 9 ~ 11에 제시되어 있는데, 각각 Fig. 9는 트랙관리 알고리즘 적용 후 확정된 트랙들의 궤적, Fig. 10은 실제 표적에 대한 확정된 트랙 궤적 그리고 Fig. 11은 매 시간마다 존재하는 임시 및 확정 트랙들의 개수를 나타낸 것이다.

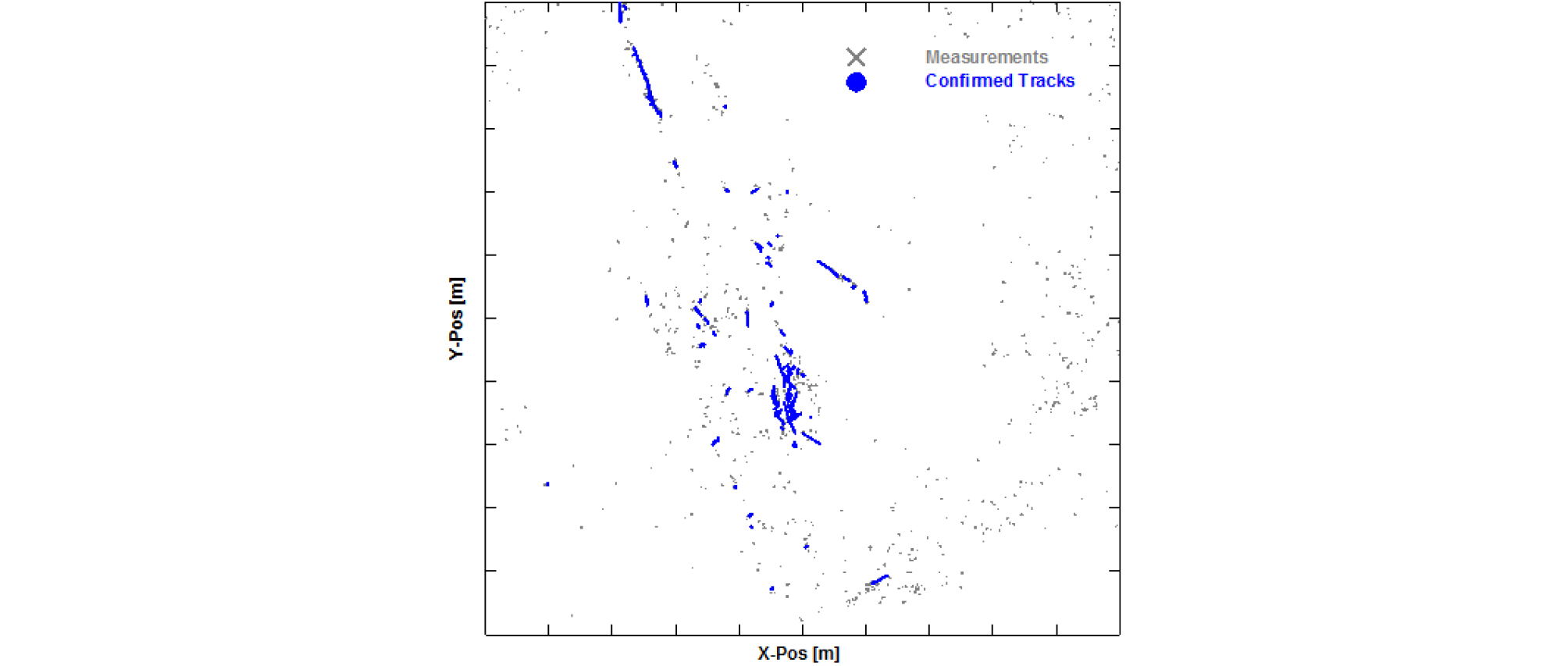
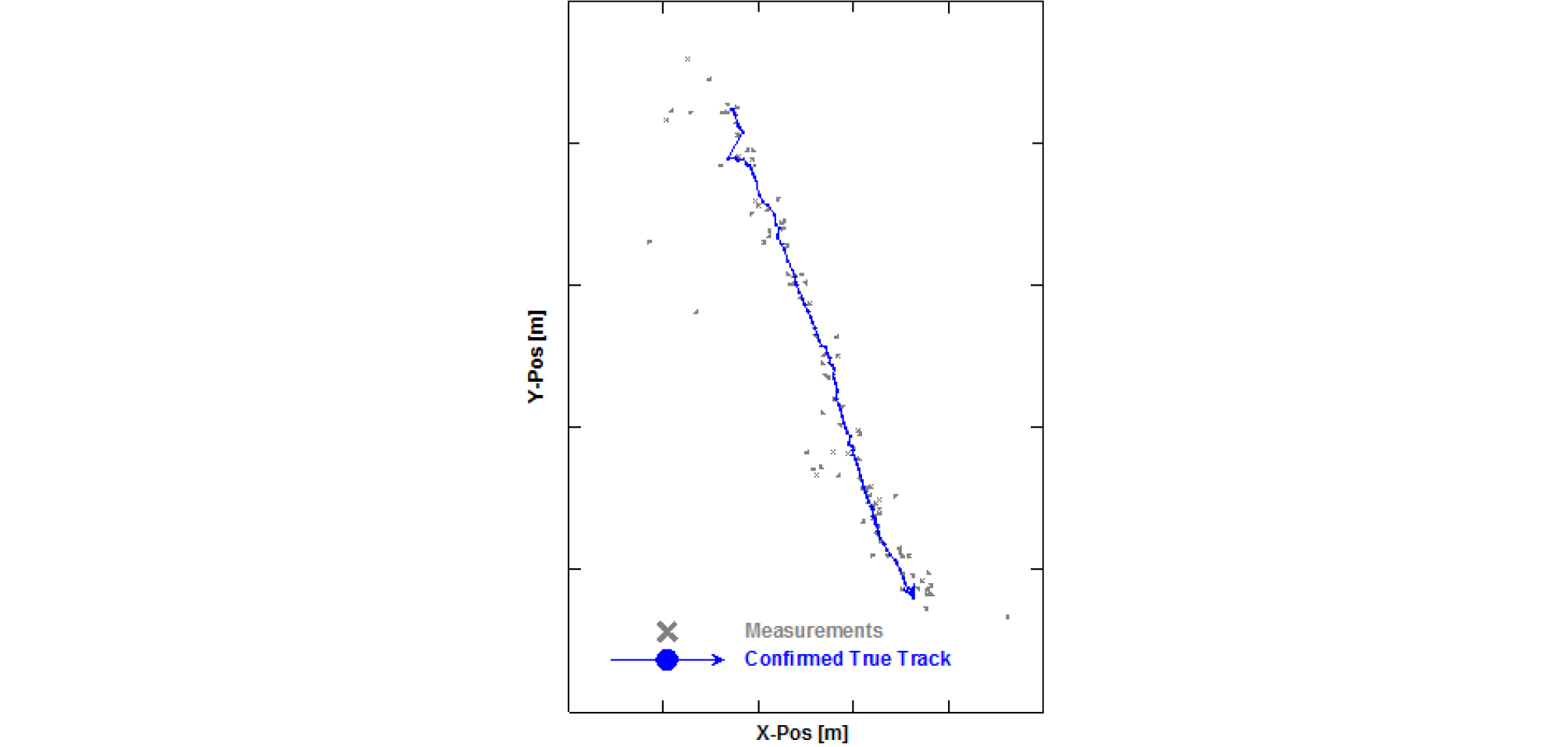

먼저 Fig. 10에서 실제 표적에 대한 탐지확률은 분석 결과 약 70 %정도로 표적을 탐지하였지만, 본 논문에서 적용한 자동 표적 추적 알고리즘 수행 시 트랙존재확률을 통해 트랙을 관리하기 때문에 효율적으로 트랙을 잘 유지하며 추적하는 것을 확인할 수 있다. 또 Figs. 9와 11을 통해 실제 표적에 대한 트랙 외에 클러터로 인한 거짓 트랙들도 생성 및 확장된 것을 볼 수 있는데, 이러한 거짓 트랙들을 최소화하기 위한 연구는 추후에 계속 진행되어야 할 것이다. 마지막으로 연산시간을 분석해본 결과 매 스캔 당 트랙관리뿐만 아니라 표적추적 알고리즘까지 모두 수행한 시간은 평균 0.24 s로 실시간 측면에서도 다중표적추적 알고리즘을 적용하는 데에 문제없을 것으로 사료된다.
VII. 모의실험
앞서 해상실험에서 자동 표적 추적 알고리즘의 성능을 분석하였지만, 실제 표적은 1개이고 단일수행이었기 때문에 각 표적추적 알고리즘이 적용된 자동 표적 추적 알고리즘에 대한 성능을 분석하기에는 다소 무리가 있다. 따라서 본 장에서 추가적으로 수영자 탐지 소나에서의 자동 표적 추적 알고리즘 성능을 모의실험을 통해 분석하고자 한다. 성능분석 대상은 단일표적추적 IPDAF, 다중표적추적 LMIPDAF이다.
7.1 모의실험 조건
시나리오는 Fig. 12와 같이 근접한 2개의 교차 표적이 존재하는 상황으로 2개 표적 모두 등속직선운동을 한다고 가정하였다. 총 200번의 몬테카를로 모의실험을 수행하였으며, 유사한 확정된 거짓트랙 개수를 맞춘 상황에서 각 알고리즘들의 통계적인 확정된 실제트랙 율 및 추정오차 등을 분석하여 성능을 분석 및 검증하였다. 모의실험에 대한 상세한 조건은 Table 2에서 확인할 수 있다.
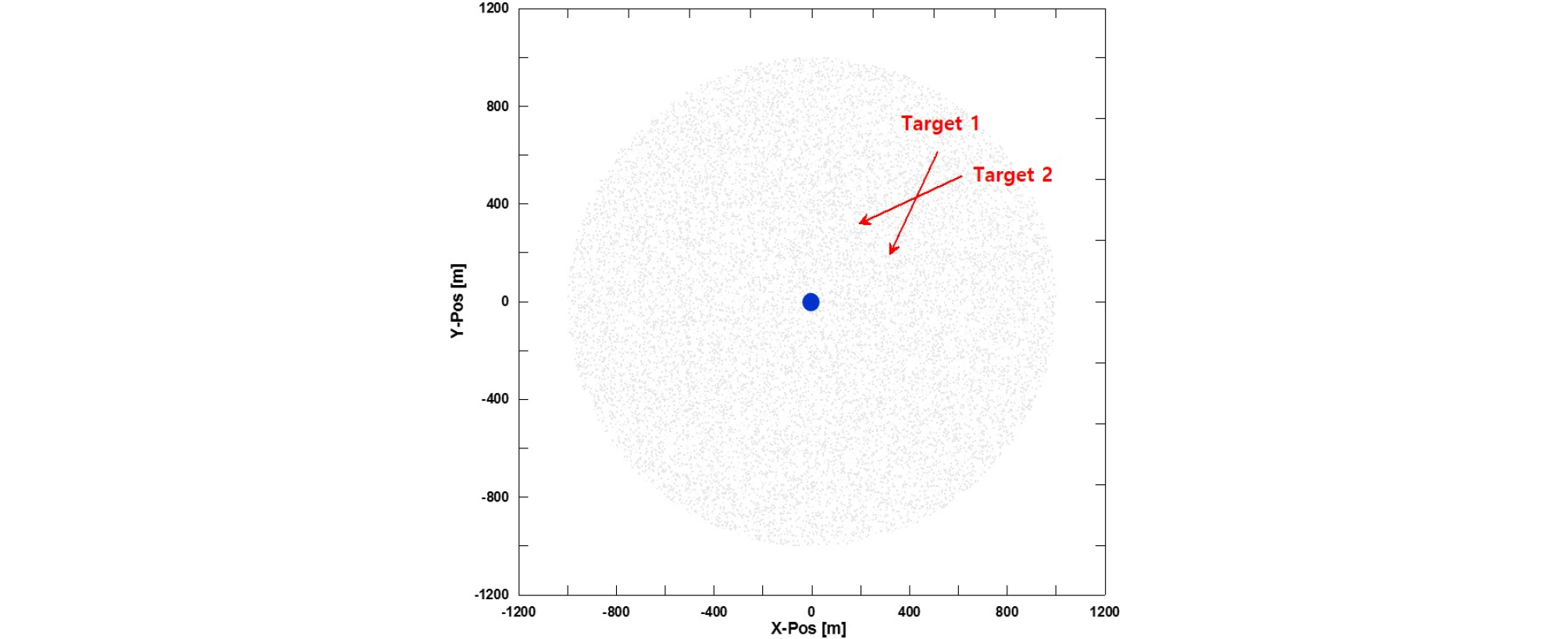
Table 2. Simulation conditions.
7.2 모의실험 결과
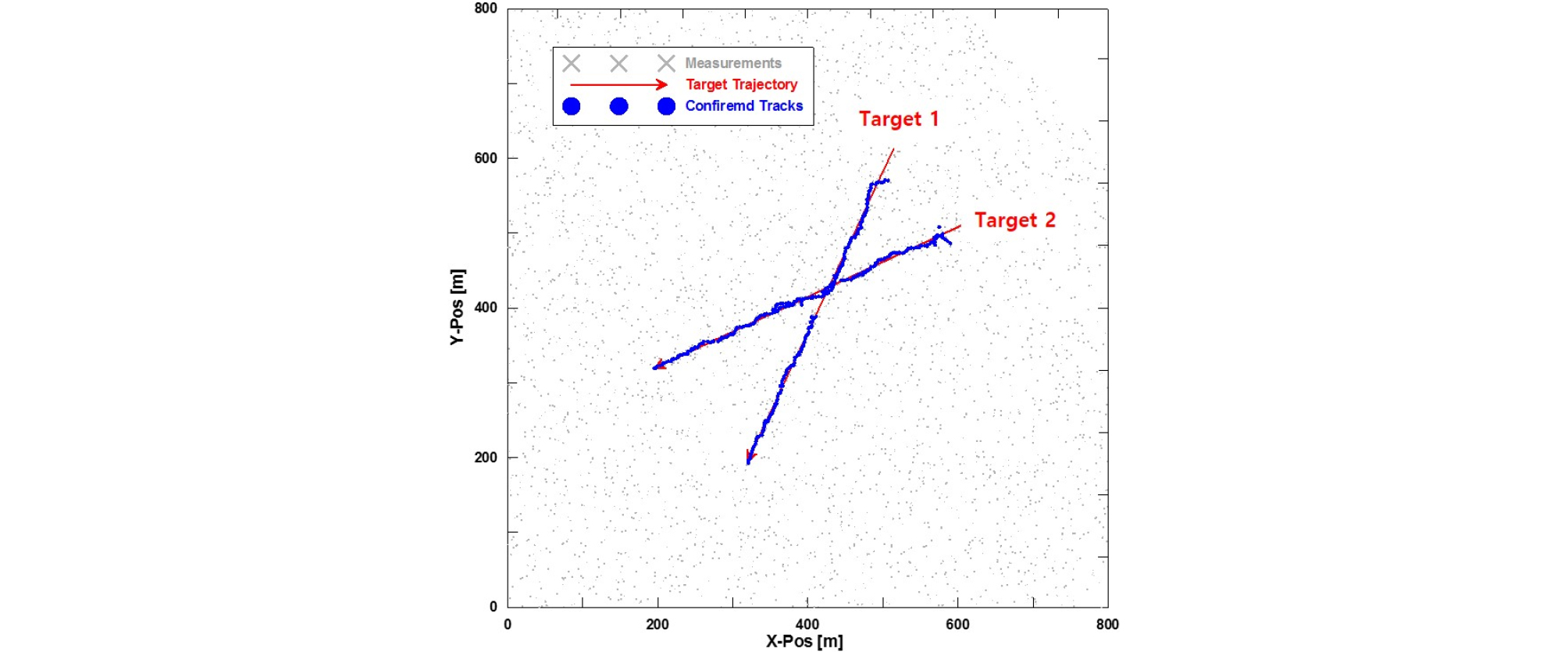
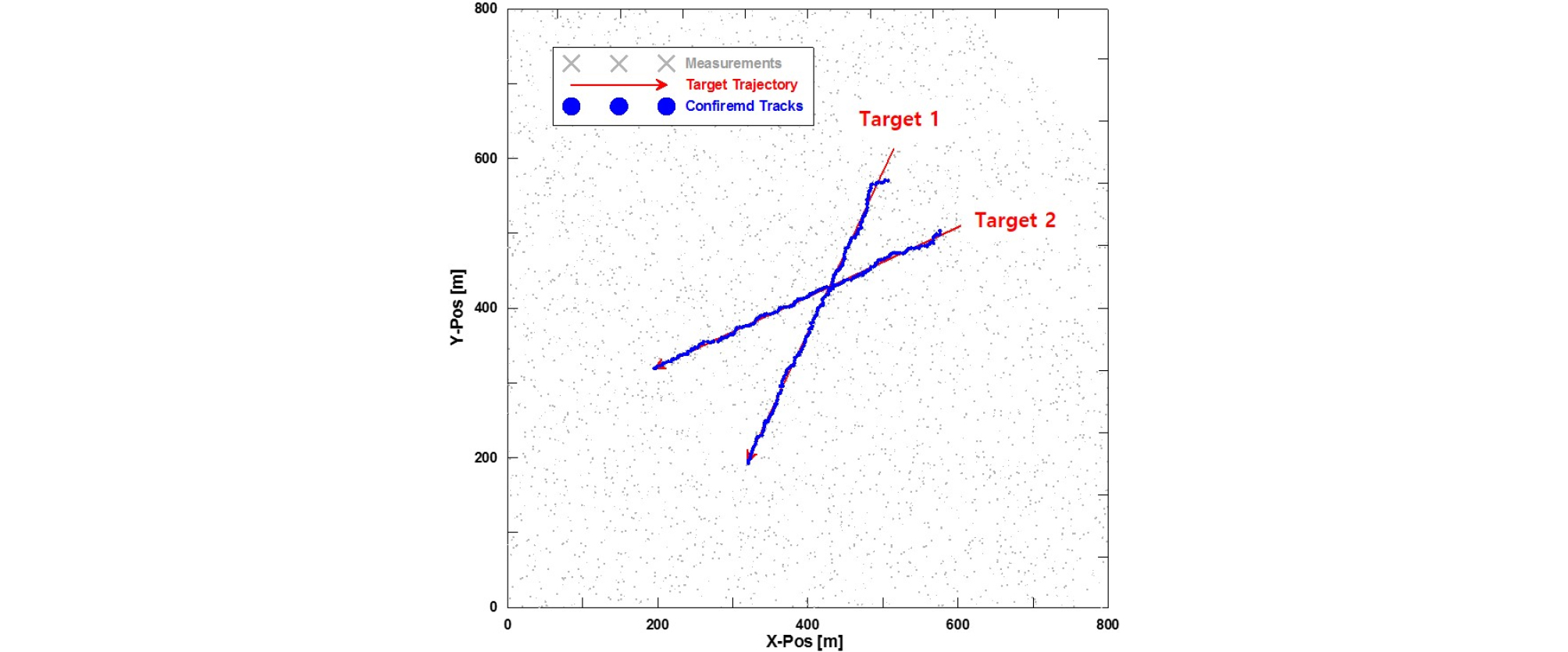
Figs. 13과 14는 단일 모의실험 결과로 자동으로 표적들에 대한 트랙을 초기화하고, 확정, 제거 등 트랙관리를 수행하며 추적하는 결과를 나타낸 것으로, Fig. 13은 IPDAF, Fig. 14는 LMIPDAF 결과이다. 교차 구간에서 IPDAF는 트랙을 놓치고 교차 구간 이후 재 초기화하여 추적을 수행하지만, LMIPDAF는 트랙을 잘 유지하며 안정적인 추적이 가능한 것을 확인할 수 있다.
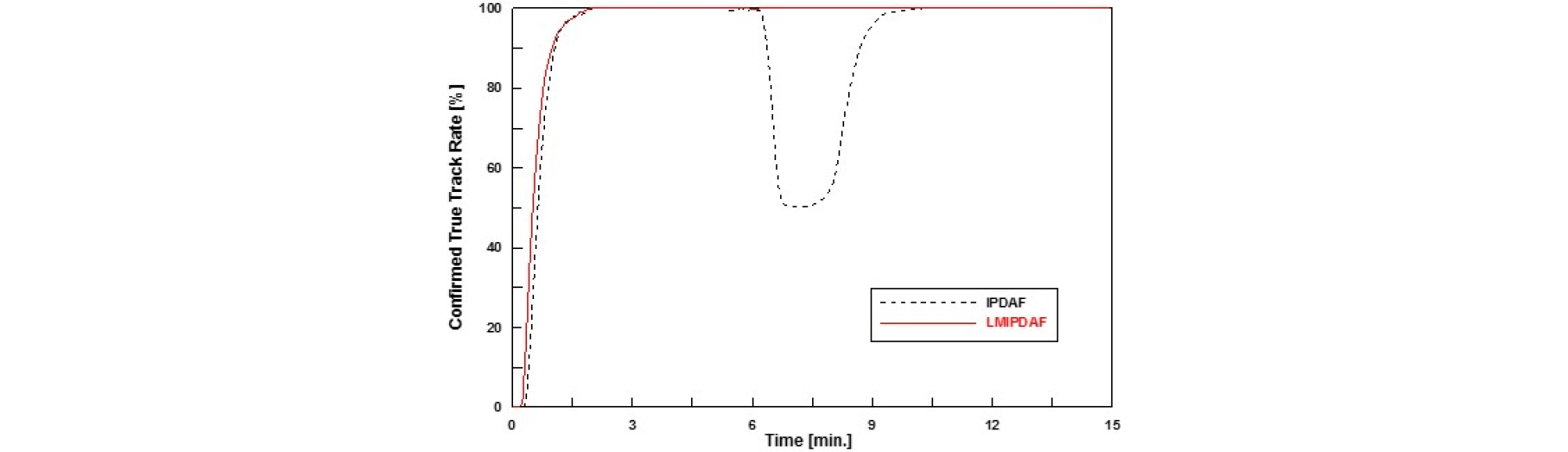
또 Fig. 15는 몬테카를로 모의실험 결과 중 확정된 실제트랙 율이다. 먼저 IPDAF와 LMIPDAF 결과를 비교해보면, 표적 교차 구간에서 확연히 성능 차이가 나타나는 것을 볼 수 있다. IPDAF는 교차 구간에서 트랙을 소실하면서 확정된 실제트랙 율이 거의 50 % 가까이 낮아지지만, LMIPDAF는 유효 탐지정보가 클러터, 현재 표적 그리고 다른 표적들로부터 까지 발생되었을 경우를 고려하기 때문에 IPDAF에 비해 트랙을 소실하지 않고 잘 유지한다.
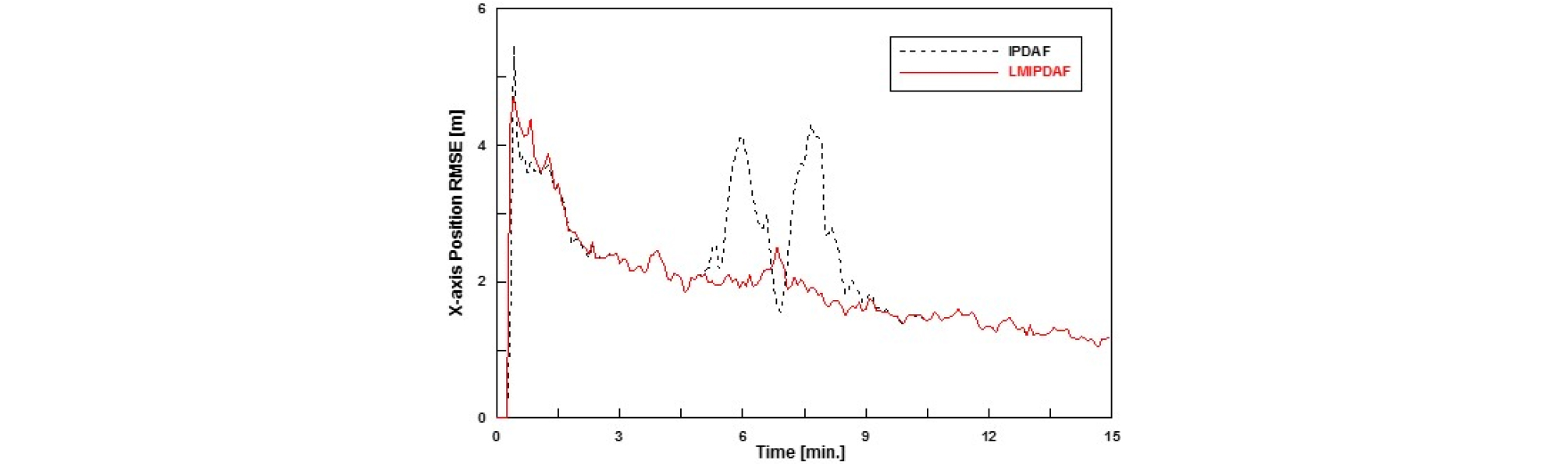
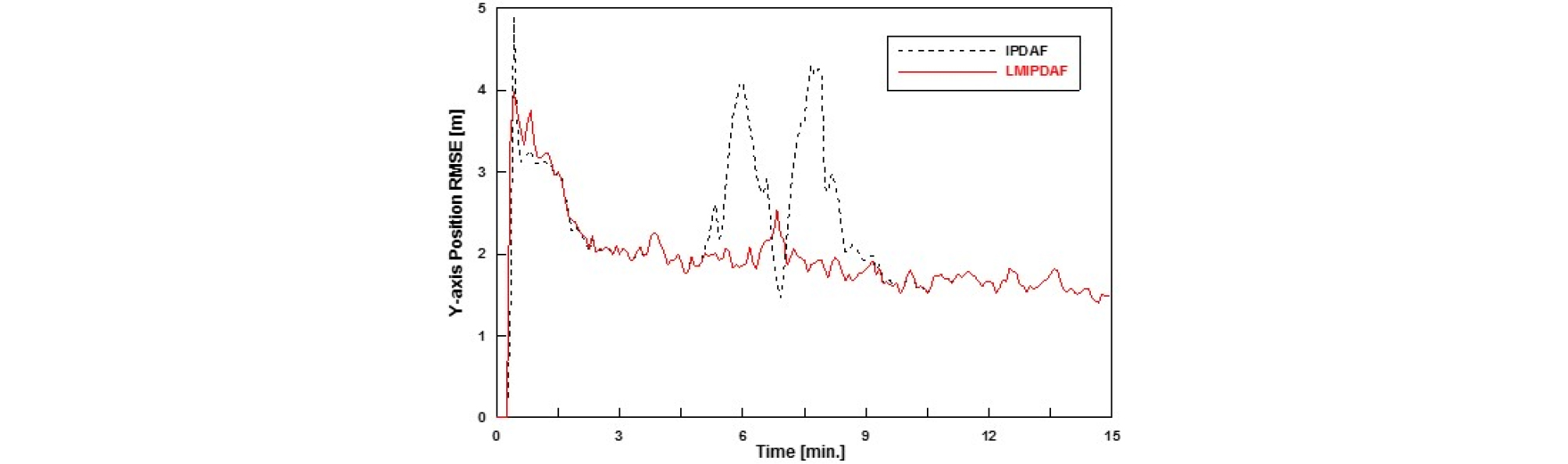
Figs. 16과 17은 확정된 실제트랙의 추정오차를 분석한 것으로 각각 x,y축에서의 위치 RMSE(Root Mean Square Error)를 나타낸 것이다. 마찬가지로 교차 구간에서 IPDAF는 추정오차가 상당히 높아지지만, LMIPDAF는 다른 구간의 RMSE와 큰 차이 없이 정확한 추정치를 제공하는 것을 알 수 있다.
VIII. 결 론
수영자 탐지 소나는 연안 군사시설 및 주요 기반시설(항만, 발전소)에 설치되어 잠수부나 수영자와 같은 소형표적을 탐지, 추적 및 식별하여 위협을 판단하는데 사용된다. 본 논문에서는 수영자 탐지 소나의 해상실험 데이터를 분석하고, 수영자 탐지 소나에 적합한 자동 표적 추적 알고리즘을 제시하였다. 제시한 알고리즘은 트랙평가수단으로 트랙존재확률을 산출하고, 이를 이용하여 트랙 초기화, 확정, 제거, 합병 등의 관리를 수행할 수 있어 자동 표적 추적 시스템을 구성하는데 적합함을 보였다. 또 단일표적추적 IPDAF 및 다중표적추적 LMIPDAF을 제시하였고, 해상실험 데이터를 이용한 성능분석과 함께 모의실험을 통하여 각 표적추적 알고리즘을 적용한 자동 표적 추적 알고리즘의 성능을 비교 및 분석하였다. 그러나 본 논문에서 분석한 해상실험 결과는 단일 수행 결과로 성능을 대표하기에는 다소 무리가 있기에, 추후에는 다양한 해양환경에서의 실측 데이터를 분석하고 추적성능을 분석하고자 한다. 또한 해양환경의 변화에 민감하지 않고 견실한 추적성능을 위한 표적추적 파라미터 추정 방안에 대해 모색하고자 한다.
